
“By 2025, large language models had processed more text than every human being in history has ever written.” That’s not a metaphor. It’s the scale at which modern AI now operates — and it’s only the beginning.
Whether you’ve used ChatGPT to draft an email, asked Gemini to summarize a research paper, or integrated an LLM API into your app, you’ve already felt the impact of large language models. But what actually is an LLM? How does it turn a prompt into a coherent, useful response? And which ones are worth your attention in 2026?
- What Are Large Language Models?
- The Architecture Behind Large Language Models
- How Large Language Models Work: A Step-by-Step Walkthrough
- Top Large Language Models in 2025: A Comparison
- Real-World Applications of Large Language Models
- Limitations and Challenges of Large Language Models
- LLM Techniques You Should Know
- The Future of Large Language Models
- Frequently Asked Questions (FAQ)
- Final Thoughts: Why Large Language Models Matter More Than Ever
From definition of large language models to updates, this guide answers all of it — no jargon gatekeeping, no fluff. Just expert-level insight, accessible to everyone from curious beginners to seasoned developers.
What Are Large Language Models?
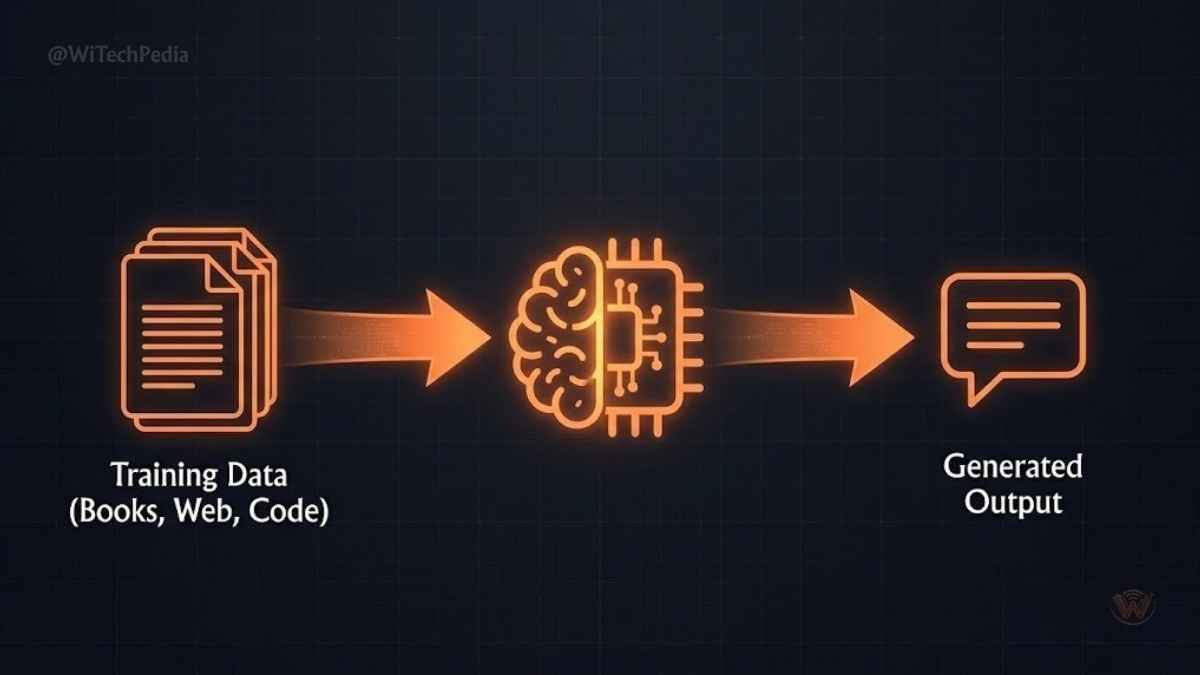
A large language model (LLM) is a type of artificial intelligence system trained on massive amounts of text data to understand, generate, and manipulate human language. The word “large” isn’t casual — these models contain billions (sometimes trillions) of parameters, the internal numerical weights that determine how the model processes and produces language.
At their core, LLMs are next-token predictors. Given a sequence of words, they predict the most likely word (or token) that should follow. Do this billions of times, at incredible speed, with patterns learned from the internet, books, code, and scientific papers — and you get a system that can write essays, debug software, translate languages, and hold nuanced conversations.
LLMs are a subset of generative AI and the foundation behind virtually every major AI product you interact with today.
The Architecture Behind Large Language Models
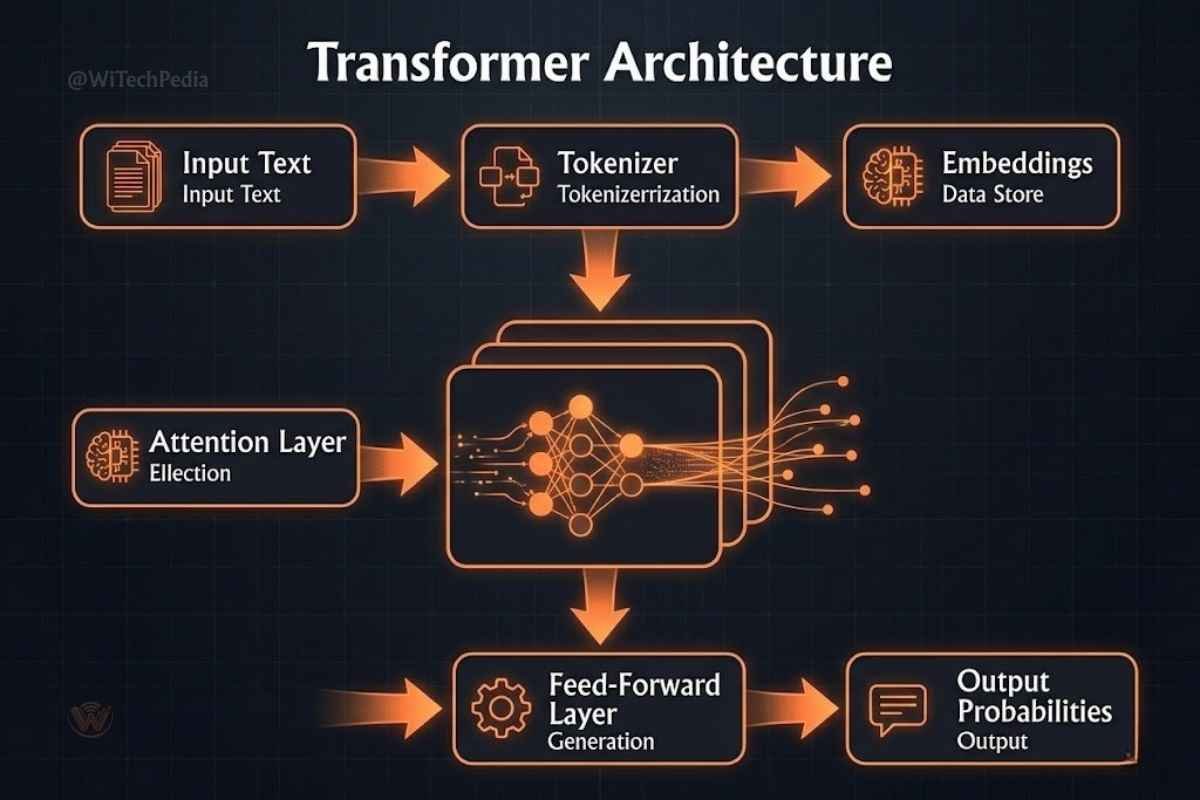
Transformers: The Engine That Changed Everything
Every modern LLM is built on the transformer architecture, introduced in the landmark 2017 Google paper “Attention Is All You Need“ by Vaswani et al. Before transformers, AI language models relied on recurrent neural networks (RNNs), which processed text sequentially — slow and prone to forgetting context over long passages.
Transformers solved this with a mechanism called self-attention, which allows the model to weigh the relevance of every word in a sentence against every other word simultaneously. This parallel processing enabled models to scale to unprecedented sizes — and with scale came emergent capabilities no one fully anticipated.
Key Components of a Transformer LLM
- Tokenization: Raw text is broken into tokens (words or sub-word units). The model processes these tokens, not characters or full words.
- Embeddings: Each token is converted into a high-dimensional numerical vector that encodes semantic meaning.
- Attention Layers: The model learns relationships between tokens. Words like “bank” get different representations depending on context (riverbank vs. financial bank).
- Feed-Forward Layers: Process the attended representations to produce output predictions.
- Output Head: Converts final representations into probability distributions over the vocabulary, selecting the next token.
Modern LLMs stack hundreds of such transformer blocks. GPT-4 is rumored to use a mixture-of-experts architecture with over 1 trillion parameters across 8 specialist sub-models — though exact figures remain undisclosed.
Training: Where the Intelligence Comes From
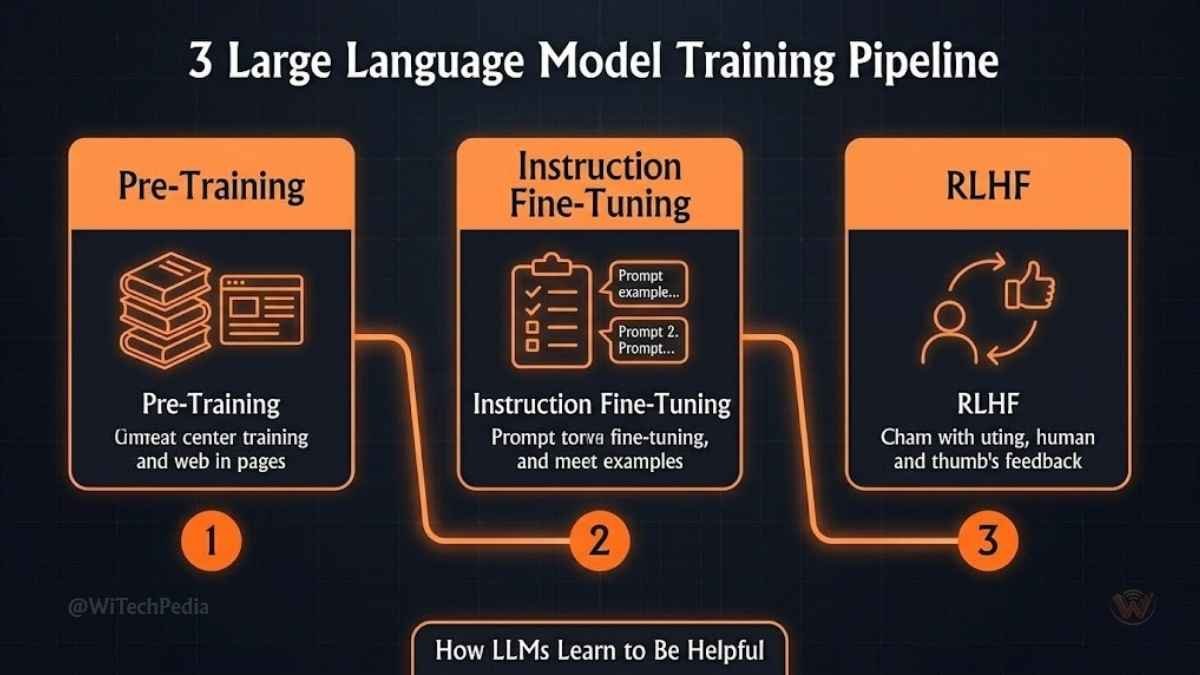
LLMs are trained in stages:
- Pre-training: The model is exposed to hundreds of billions of tokens (web text, books, code, scientific papers) and learns to predict the next token. This is unsupervised and computationally expensive — GPT-4’s training reportedly cost over $100 million.
- Fine-tuning / Instruction Tuning: The model is trained on curated prompt-response pairs to follow instructions.
- RLHF (Reinforcement Learning from Human Feedback): Human raters score model outputs for helpfulness, accuracy, and safety. The model is further trained to maximize these scores, producing more aligned behavior.
How Large Language Models Work: A Step-by-Step Walkthrough
Understanding how LLMs generate text demystifies the magic. Here’s what happens when you type a prompt:
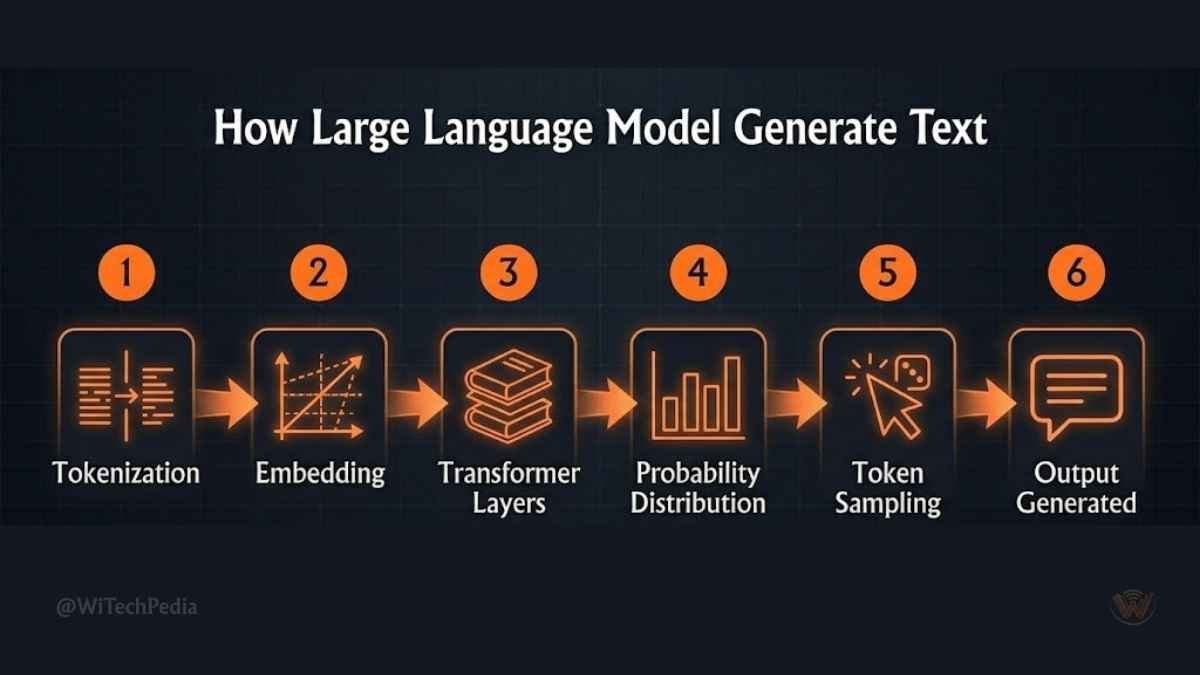
- Tokenization: Your input is split into tokens. “How do LLMs work?” might become
["How", " do", " LL", "Ms", " work", "?"]. - Embedding lookup: Each token is mapped to a dense vector in a high-dimensional space.
- Forward pass through transformer layers: Attention mechanisms compute relationships; feed-forward layers refine representations.
- Probability distribution: The model outputs probabilities over its vocabulary (e.g., 50,000+ tokens) for what comes next.
- Sampling strategy: The system uses temperature, top-k, or top-p sampling to select the next token. Lower temperature = more deterministic; higher = more creative.
- Autoregressive generation: The selected token is appended to the input, and the process repeats until a stop token or length limit is reached.
This loop runs thousands of times per response — in milliseconds on modern inference hardware.
Top Large Language Models in 2025: A Comparison

The LLM landscape has evolved rapidly. Here’s how the leading models stack up:
| Model | Developer | Parameters (est.) | Context Window | Key Strength | Best For |
|---|---|---|---|---|---|
| GPT-4o | OpenAI | ~1T (MoE) | 128K tokens | Multimodal reasoning | General-purpose, coding, vision |
| Claude 3.7 Sonnet | Anthropic | Undisclosed | 200K tokens | Long-context, safety | Research, document analysis |
| Gemini 2.5 Pro | Google DeepMind | Undisclosed | 1M tokens | Massive context, multimodal | Scientific, coding, data |
| Llama 3.1 405B | Meta AI | 405B | 128K tokens | Open source | Self-hosted, research |
| Mistral Large 2 | Mistral AI | ~123B | 128K tokens | Efficiency, multilingual | European enterprise, API |
| DeepSeek-V3 | DeepSeek | 671B (MoE) | 128K tokens | Cost-efficiency | Cost-sensitive deployments |
| Command R+ | Cohere | ~104B | 128K tokens | RAG optimization | Enterprise search, grounding |
Editorial insight: The gap between open-source and proprietary models has narrowed dramatically. Meta’s Llama 3.1 405B competes meaningfully with GPT-4 on many benchmarks — signaling a democratization of frontier AI capability.
- Check out our complete list of the Best Large Language Models of 2026 guide for better understanding before using any LLM.
Real-World Applications of Large Language Models
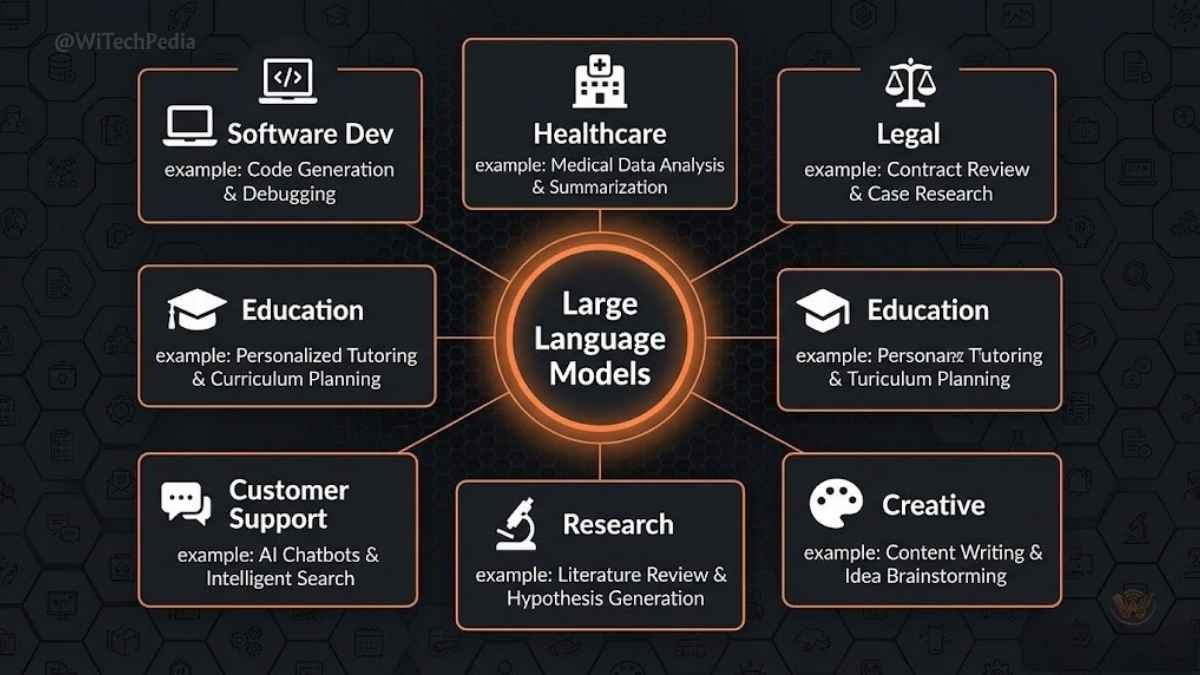
Large language models aren’t just research curiosities. They’re reshaping entire industries:
1. Software Development & DevOps
LLMs power AI coding assistants like GitHub Copilot, Cursor, and Amazon CodeWhisperer. Developers use them to:
- Generate boilerplate code in seconds
- Debug and explain complex error messages
- Write unit tests automatically
- Convert code between languages (Python → TypeScript, SQL → Pandas)
Real-world impact: GitHub reports that developers using Copilot complete tasks up to 55% faster.
2. Customer Support & Enterprise Automation
Companies deploy LLM-powered chatbots that handle thousands of simultaneous conversations with human-level coherence. Unlike rule-based systems, LLMs understand intent, handle edge cases, and escalate appropriately. Platforms like Salesforce Einstein and ServiceNow Now Assist are built on this foundation.
3. Healthcare & Medical Research
LLMs assist physicians with clinical documentation, differential diagnosis support, and literature review. Models fine-tuned on medical data (like Google’s Med-PaLM 2) have passed the U.S. Medical Licensing Examination with expert-level scores.
4. Legal & Compliance
Law firms use LLMs to review contracts at scale, identify risk clauses, and generate first-draft summaries of lengthy regulatory documents — work that previously took paralegals weeks.
5. Creative & Content Industries
From screenwriting assistance to personalized marketing copy, LLMs are embedded in tools like Jasper, Notion AI, and Adobe Firefly’s text features. They assist with ideation, drafting, and editing — amplifying human creativity rather than replacing it.
6. Education & Personalized Learning
Adaptive tutoring systems powered by LLMs provide one-on-one instruction at scale. Khan Academy’s Khanmigo, built on GPT-4, offers Socratic tutoring that guides students through problems rather than just giving answers.
7. Scientific Research
LLMs accelerate literature synthesis, hypothesis generation, and data annotation in fields from climate science to drug discovery. DeepMind’s AlphaFold combined deep learning with protein sequence understanding — a direct cousin of LLM-style architectures.
Limitations and Challenges of Large Language Models

Honesty matters. LLMs are powerful but imperfect. Key limitations include:
Hallucinations
LLMs sometimes generate confident, fluent — and completely false — information. They do not “know” facts; they predict likely token sequences. Without retrieval augmentation or grounding, factual errors are inevitable.
Context Window Limits
Even at 1M tokens (Gemini 2.5 Pro), there are limits to how much information an LLM can process at once. Very long documents, codebases, or multi-session memory require external solutions like vector databases and RAG pipelines.
Reasoning Gaps
LLMs can struggle with multi-step logical reasoning, complex mathematics, and spatial tasks — though techniques like chain-of-thought prompting and tool use (calling calculators, code interpreters) significantly mitigate this.
Bias and Safety
Trained on internet text, LLMs can reproduce and amplify societal biases. Responsible deployment requires careful safety evaluation, red-teaming, and ongoing monitoring.
Computational Cost
Inference at scale is expensive. Running a 70B-parameter model requires significant GPU infrastructure. This creates access disparities and environmental concerns — a full GPT-4 training run emits an estimated 500+ tons of CO₂.
LLM Techniques You Should Know
For developers and practitioners working with large language models, these techniques are essential:
Prompt Engineering
The art of structuring inputs to elicit better outputs. Techniques include:
- Zero-shot prompting: No examples given; rely on the model’s pre-trained knowledge.
- Few-shot prompting: Provide 2–5 examples in the prompt to establish a pattern.
- Chain-of-thought (CoT): Instruct the model to “think step by step” before answering, dramatically improving reasoning accuracy.
- System prompts: Set behavioral context before the conversation begins.
Retrieval-Augmented Generation (RAG)
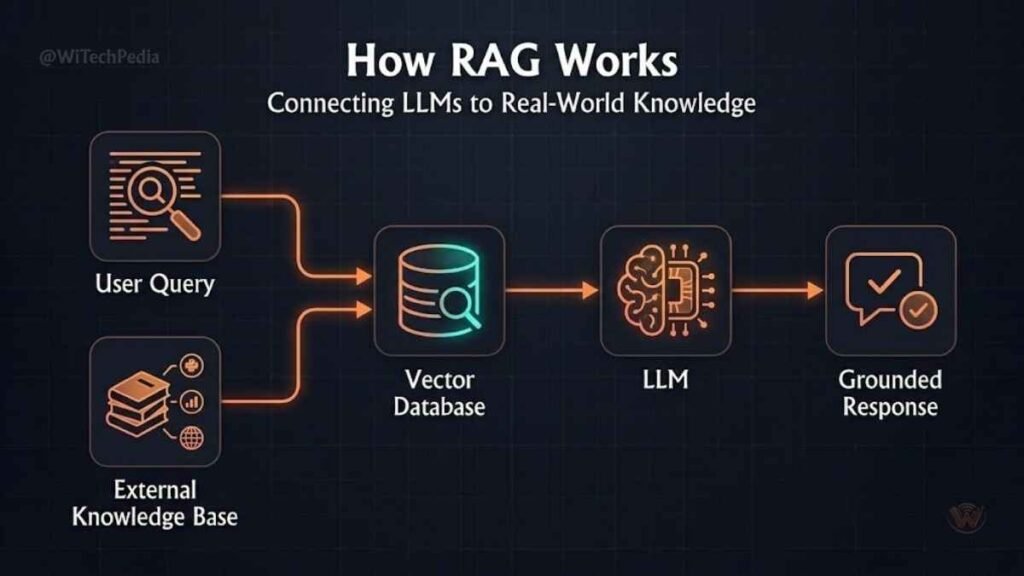
RAG connects LLMs to external knowledge bases. The system retrieves relevant documents, injects them into the prompt, and lets the LLM generate grounded, citable responses. Essential for enterprise deployments where accuracy matters.
Fine-Tuning
Adapting a pre-trained LLM to a specific domain or task using a smaller, curated dataset. Methods like LoRA (Low-Rank Adaptation) allow fine-tuning on consumer-grade GPUs with minimal performance loss versus full fine-tuning.
Agents and Tool Use
Modern LLMs can act as intelligent agents — planning multi-step tasks, calling APIs, browsing the web, writing and executing code, and managing files. Frameworks like LangChain, AutoGen, and OpenAI’s Assistants API power this paradigm. See WiTechPedia’s guide to AI agents.
The Future of Large Language Models
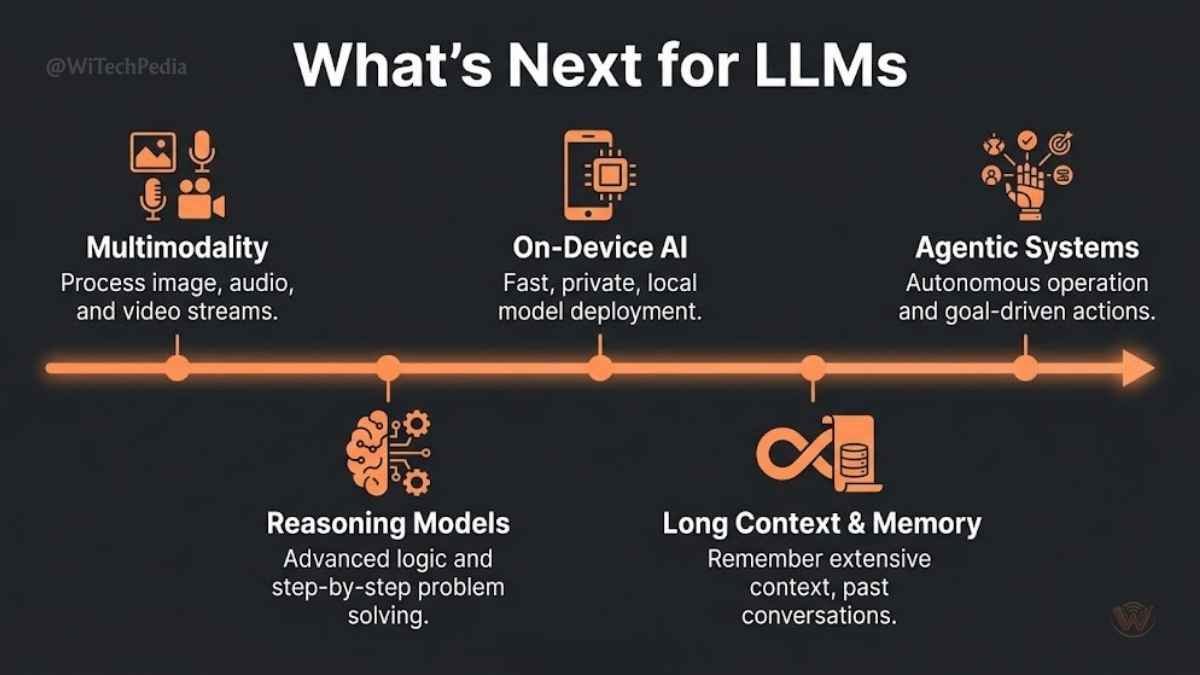
The trajectory is clear, and the pace is accelerating:
- Multimodality: LLMs increasingly handle images, audio, video, and structured data alongside text. GPT-4o and Gemini 2.5 represent the current frontier.
- Reasoning models: OpenAI’s o3, Google’s Gemini 2.5 Pro with extended thinking, and Anthropic’s Claude 3.7 with extended thinking demonstrate that slow, deliberate reasoning can dramatically improve accuracy on complex tasks.
- Efficiency: Smaller, faster models (Llama 3.2, Phi-4, Gemma 3) are closing the gap with frontier giants at a fraction of the compute — enabling on-device AI.
- Long-context and memory: Models with million-token context windows and persistent memory are eliminating the statefulness problem that once made LLM applications brittle.
- Agentic systems: The shift from LLMs as chatbots to LLMs as autonomous agents capable of completing complex, multi-day workflows is the defining next chapter.
Frequently Asked Questions (FAQ)
What is a large language model in simple terms?
A large language model is an AI system trained on vast amounts of text to understand and generate human language. It works by predicting the most likely next word (or token) based on everything it has learned during training. The “large” refers to the billions or trillions of mathematical parameters that store this learned knowledge.
What is the difference between an LLM and a traditional AI model?
Traditional AI models are typically narrow — designed for one specific task, like image classification or spam filtering. LLMs are generalist: trained on diverse text data, they can handle writing, coding, reasoning, translation, summarization, and more within a single model. They also learn from context during a conversation, unlike most traditional models.
Are large language models the same as ChatGPT?
Not exactly. ChatGPT is a product built on top of an LLM (GPT-4o or GPT-3.5). The LLM is the underlying AI model; ChatGPT is the conversational interface layered on top, with additional safety tuning and product features. Other LLM-based products include Claude (Anthropic), Gemini (Google), and Copilot (Microsoft).
How are large language models trained?
LLMs are trained in multiple phases: first, unsupervised pre-training on massive text datasets (hundreds of billions of tokens from the web, books, code); then instruction fine-tuning on curated examples; and finally, reinforcement learning from human feedback (RLHF) to align the model with human preferences for helpfulness, accuracy, and safety.
What are the biggest risks of large language models?
The main risks include: (1) Hallucinations — generating plausible but false information; (2) Bias — reproducing harmful biases present in training data; (3) Misuse — generating disinformation, spam, or malicious code; (4) Privacy — potential leakage of training data or misuse of personal information; and (5) Dependency — uncritical over-reliance on AI-generated content in high-stakes decisions. Responsible deployment requires addressing all of these through technical and policy safeguards.
Can large language models truly understand language?
This is one of the most debated questions in AI. LLMs demonstrate impressive language competence — they can solve analogies, detect sarcasm, and reason about hypotheticals. Whether this constitutes “understanding” in a philosophical or cognitive sense remains contested. Most researchers agree LLMs are sophisticated pattern matchers that produce functionally intelligent outputs, without the grounded, embodied understanding humans possess.
What is the best large language model in 2025?
There is no single “best” LLM — it depends on your use case. GPT-4o excels at general-purpose reasoning and multimodal tasks. Claude 3.7 Sonnet leads on long-context document analysis and safety. Gemini 2.5 Pro is a powerhouse for coding and scientific reasoning. Llama 3.1 405B is the top open-source option for teams that need full control. Evaluate based on context window, pricing, latency, and domain-specific benchmarks. Check out out complete list of the Best Large Language Models for 2026.
Final Thoughts: Why Large Language Models Matter More Than Ever
Large language models represent the most transformative technology of the current decade. Here are the key takeaways:
- LLMs are transformer-based AI systems trained on massive text corpora to understand and generate language — the foundation of nearly every modern AI product.
- Scale drives capability: the jump from billions to hundreds of billions of parameters produces qualitative leaps in reasoning, creativity, and task generalization.
- Real-world impact is already here: from accelerating software development to transforming healthcare documentation, LLMs are active tools in professional workflows worldwide.
- Limitations are real but manageable: hallucinations, bias, and cost are solvable with the right architecture — RAG, fine-tuning, and agent frameworks are closing the gaps.
- The next frontier is agentic AI: LLMs are evolving from conversational tools into autonomous agents capable of multi-step reasoning, planning, and execution.
The question is no longer whether large language models will reshape your industry — it’s whether you’ll be ready when they do.
Stay ahead of AI. Subscribe to the WiTechPedia newsletter for weekly deep dives into the technologies shaping our world. Or explore our full guide to Generative AI to continue your journey.