
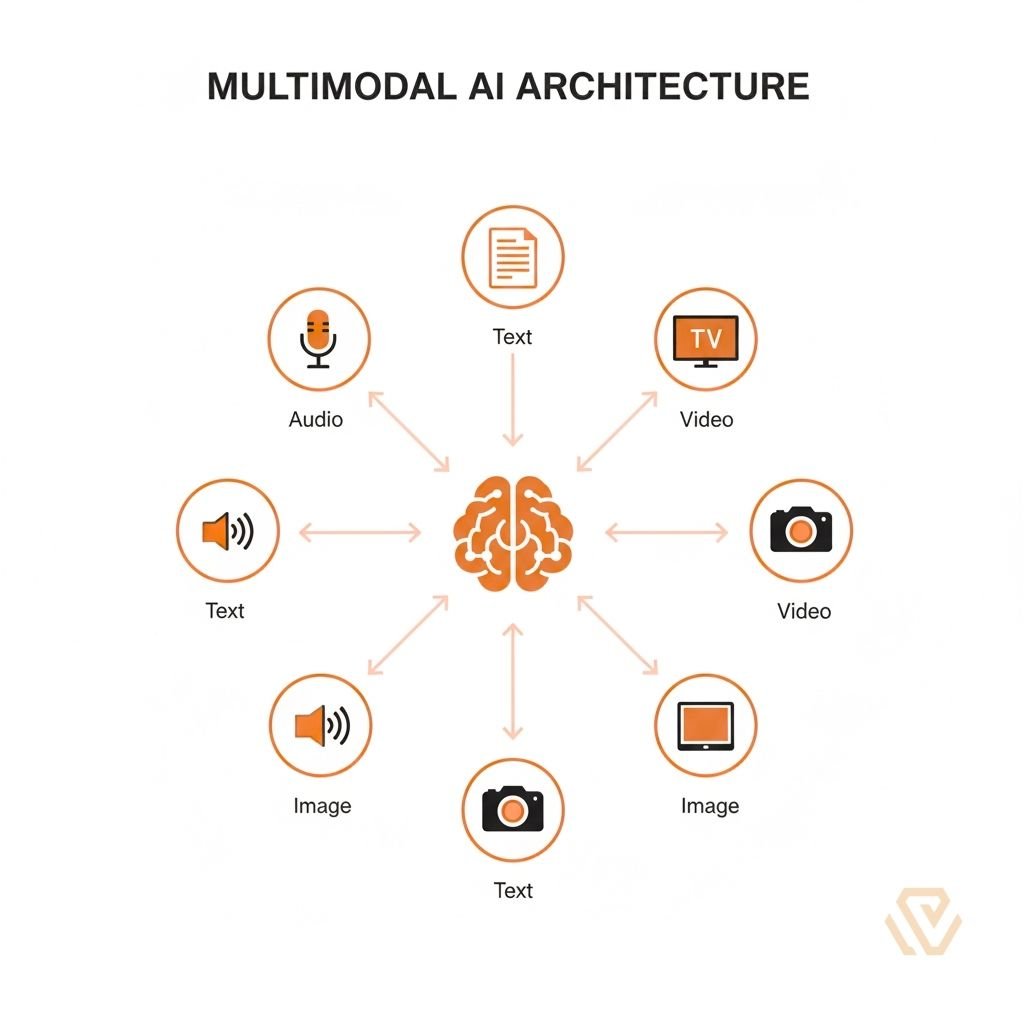
Multimodal AI is a type of artificial intelligence that can process, understand, and generate information using multiple types of data—or “modalities”—simultaneously. Unlike traditional AI, which is often limited to a single input type (like text-only), Multimodal AI integrates text, images, audio, video, and sensor data to create a more human-like understanding of the world.
What is Multimodal AI?
At its core, Multimodal AI mimics human perception. Humans don’t just “read” the world; we see a person’s expression (vision), hear their tone of voice (audio), and listen to their words (text) to understand the full context.
Multimodal AI uses deep learning architectures to bridge the gap between these different data formats, allowing the model to find relationships between a written description and a visual object.
Key Modalities in Multimodal AI
Artificial Intelligence classifies different data streams as “modalities.” The most common combinations in 2026 include:
- Text-to-Image / Image-to-Text: Models that describe what is in a photo or generate art from a prompt (e.g., DALL-E 3).
- Video Understanding: Analyzing movement and audio within a video file to provide summaries.
- Audio-to-Text: Highly accurate transcription that also understands emotional context or background noise.
- Sensor Data: Integrating infrared, LIDAR, or thermal data (common in Robotics and Physical AI).
How Multimodal AI Works
The technical “magic” of Multimodal AI happens through a process called Data Alignment and Fusion.
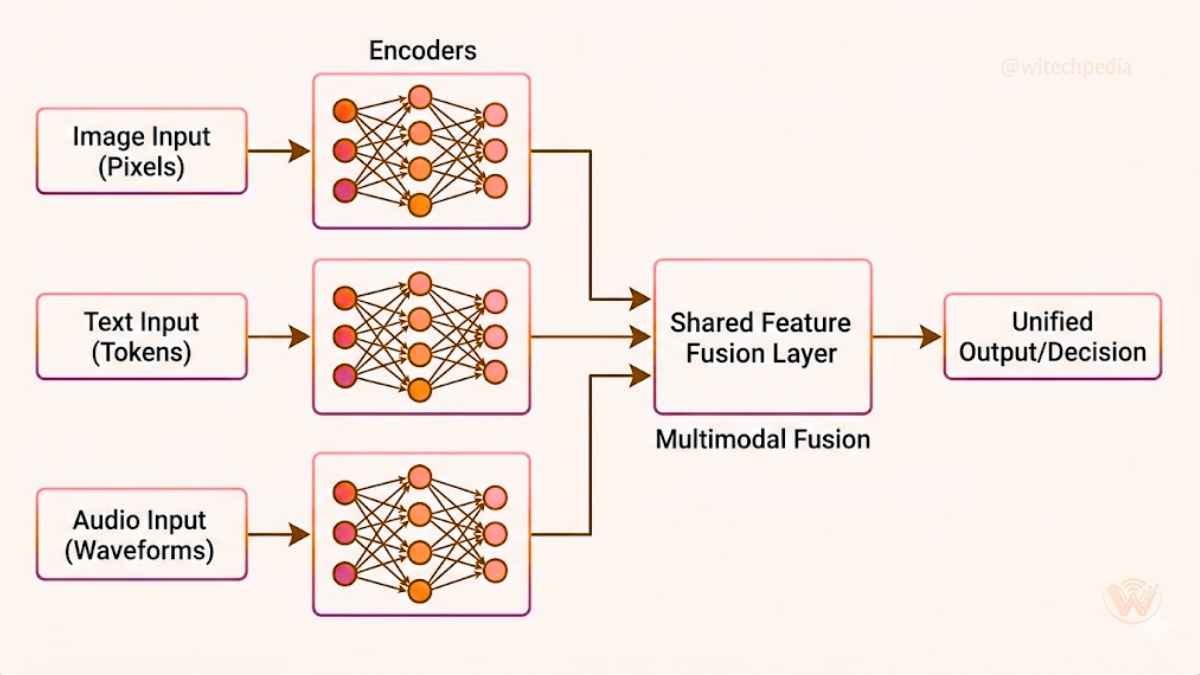
1. Encoding
Each data type is processed by its own “encoder.” For example, a Vision Transformer (ViT) might handle images, while a Large Language Model (LLM) handles text.
2. Fusion Techniques
- Early Fusion: Merging the data at the feature level before the model makes any decisions.
- Late Fusion: Processing each modality separately and then merging the results at the very end to reach a conclusion.
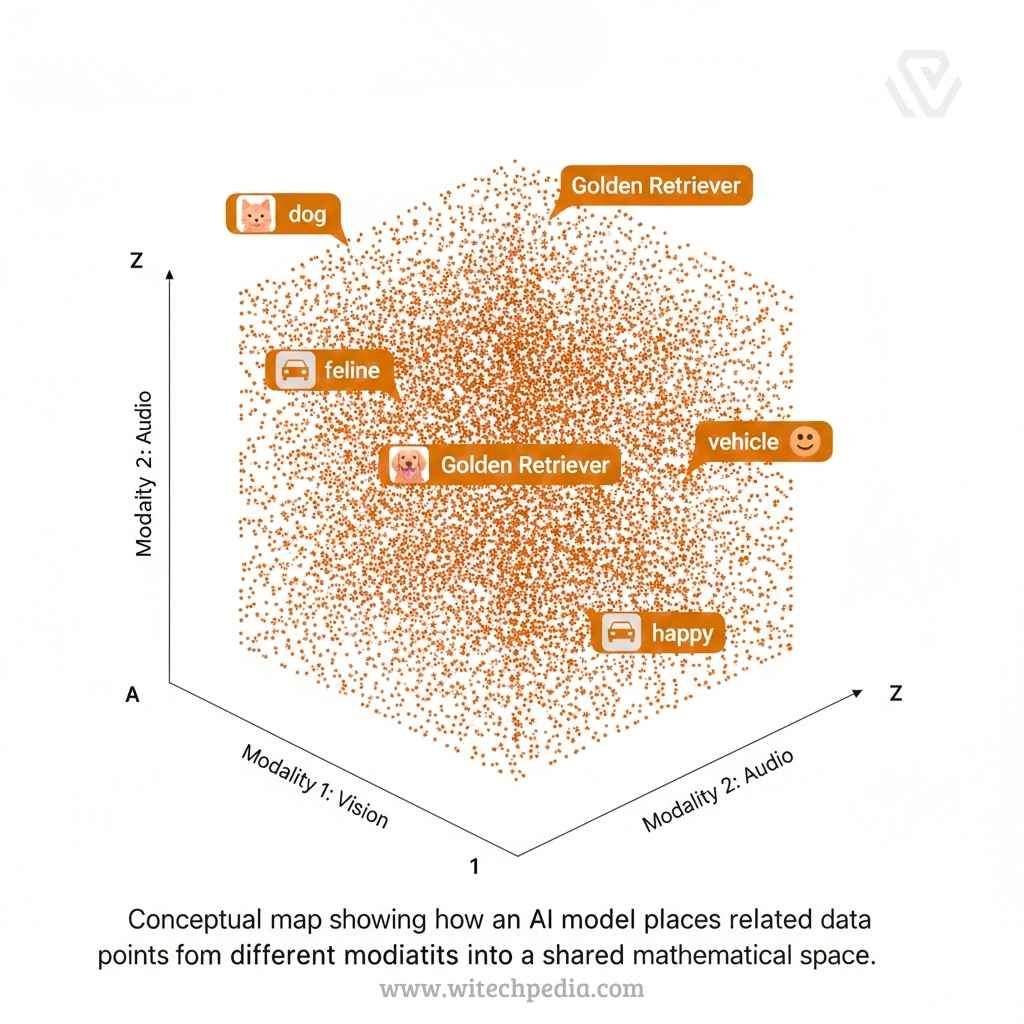
3. Joint Embedding Space
The model creates a mathematical “map” where a picture of a dog and the word “dog” are placed in the same location, allowing the AI to understand they represent the same concept.
Famous Multimodal Models (2026)
As of 2026, several flagship models dominate the landscape:
| Model Name | Developer | Key Strengths |
| GPT-4o | OpenAI | Native omni-capability; real-time voice and vision. |
| Gemini 1.5 Pro | Massive context window; exceptional video analysis. | |
| Claude 3.5 Sonnet | Anthropic | High-level reasoning with visual data. |
| LLaVA | Open Source | Leading open-source large language and vision assistant. |
Real-World Applications
1. Healthcare
AI can analyze a patient’s MRI scan (image) alongside their medical history (text) and heart rate logs (sensor data) to provide a more accurate diagnosis than a unimodal system.
2. Autonomous Vehicles
Self-driving cars use multimodal inputs—combining camera feeds, LIDAR pulses, and GPS data—to navigate complex urban environments safely.

3. Content Creation
Creators use multimodal tools to turn text scripts directly into edited videos with synthetic voiceovers and matching background music.
Benefits and Challenges of Multimodal AI
Benefits
Challenges
- Holistic Understanding: Provides more contextually aware answers.
- Accessibility: Better tools for the visually or hearing impaired.
- Efficiency: Consolidating multiple AI tasks into one single model.
- Computational Cost: Requires massive GPU power to process video and high-res images.
- Data Bias: If image data and text data have different biases, they can compound within the model.
Why Multimodal AI Matters in 2026
Modern technology demands natural, fluid interactions. We expect machines to understand our world exactly as we do. Multimodal AI delivers this seamless, intuitive experience. It pushes the absolute boundaries of what digital machines can achieve.
Frequently Asked Questions (FAQs)
What is the main difference between unimodal and multimodal AI?
Unimodal AI handles exactly one data type. Multimodal AI processes several different data types at once.
Can Multimodal AI understand human emotions?
Yes. Advanced models analyze voice tone, text sentiment, and facial expressions to interpret emotions accurately.
Which companies lead Multimodal AI development?
Tech giants like Google, OpenAI, and Meta drive the most significant advancements in this specific field today.
Does Multimodal AI require more computing power?
Absolutely. Processing video, audio, and text simultaneously demands massive computational resources and powerful servers.
Will Multimodal AI replace human jobs?
This technology augments human capabilities. It creates exciting new opportunities rather than simply replacing creative roles.
Glossary of Terms
- Modality: A specific channel of communication or data (e.g., text, image).
- Tokenization: The process of breaking down data into smaller pieces the AI can understand.
- Latent Space: The hidden mathematical “map” where the AI stores conceptual relationships.