In 2012, a neural network stunned the world by slashing the error rate on the ImageNet image classification benchmark by nearly 11 percentage points — more than all previous years combined. That single moment didn’t just win a competition. It ignited the deep learning revolution that now underlies nearly every major AI breakthrough you’ve heard of.
Whether it’s ChatGPT writing essays, a radiologist’s AI spotting cancer earlier than the human eye, or your phone unlocking with your face — deep learning is the engine running underneath. This guide breaks it all down: how it works, why it’s so powerful, which tools drive it, and where it’s headed next.
- What Is Deep Learning?
- Deep Learning vs. Machine Learning vs. AI
- How Does Deep Learning Work?
- Core Architectures in Deep Learning
- Deep Learning Frameworks: The Developer’s Toolkit
- Real-World Applications of Deep Learning
- Key Challenges in Deep Learning
- The Hardware Powering Deep Learning
- Deep Learning vs. Machine Learning: When to Use Which
- Getting Started with Deep Learning
- Frequently Asked Questions (FAQs)
- The Future of Deep Learning
- Conclusion: Why Deep Learning Is the Most Important Technology of Our Era
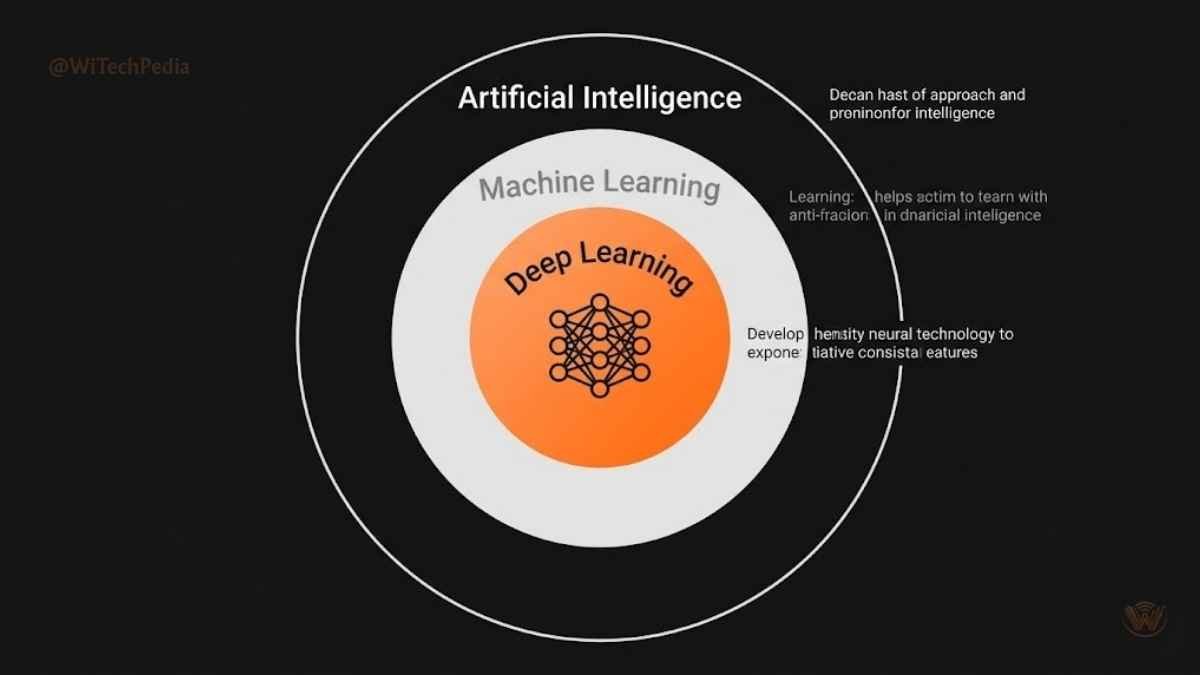
What Is Deep Learning?
Deep learning is a subfield of machine learning — itself a branch of artificial intelligence (AI) — that uses layered artificial neural networks to learn patterns from data. The word deep refers to the many layers in these networks — sometimes hundreds or thousands — each one learning increasingly abstract representations of the input.
Think of it this way: when you show a deep learning model millions of cat photos, the first layers learn to detect edges. The next layers learn shapes. The deeper layers eventually learn the concept of “cat” — without ever being explicitly programmed what a cat is.
That’s the paradigm shift. Instead of hand-crafting rules, you feed the system data and let it discover the rules itself.
Deep Learning vs. Machine Learning vs. AI
People often use these three terms interchangeably, but they’re nested concepts — not synonyms.
| Concept | Definition | Scope |
|---|---|---|
| Artificial Intelligence (AI) | Any system that simulates human intelligence | Broadest |
| Machine Learning (ML) | AI systems that learn from data without explicit programming | Subset of AI |
| Deep Learning (DL) | ML using multi-layered neural networks for complex pattern recognition | Subset of ML |
| Traditional ML | ML using hand-crafted features (e.g., decision trees, SVM) | Also a subset of ML |
The key distinction: traditional ML relies on humans to identify and engineer features from data. Deep learning automates this process — the model finds the features itself, making it dramatically more powerful for unstructured data like images, audio, and text.
How Does Deep Learning Work?
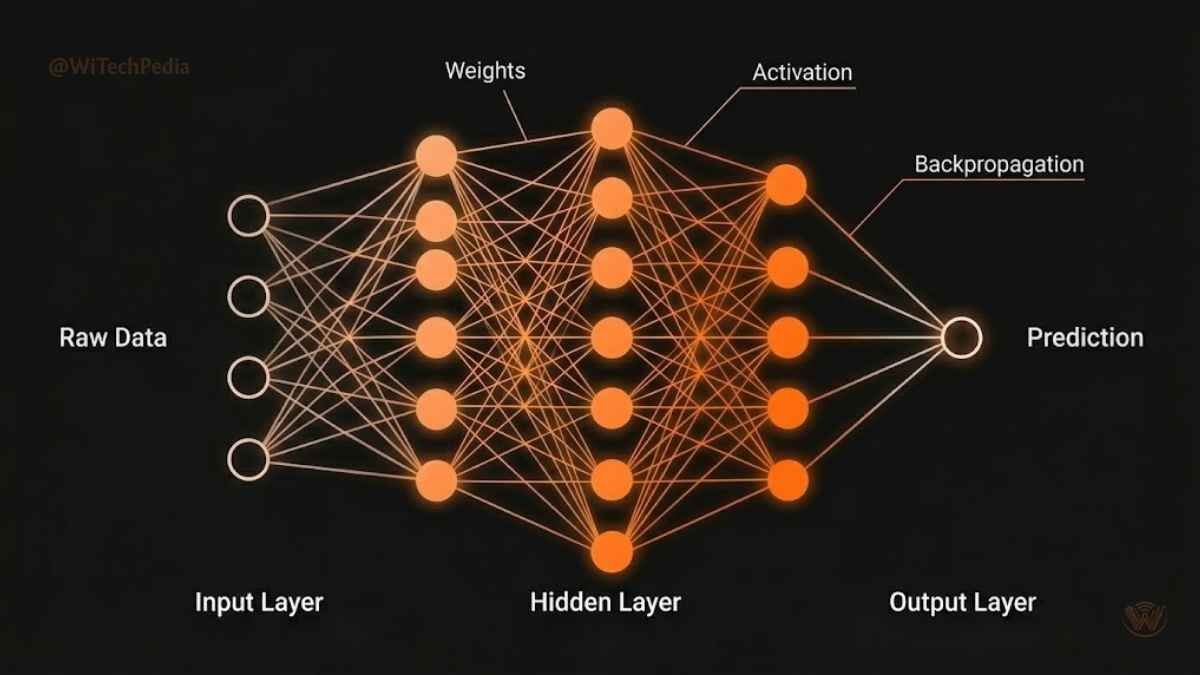
The Anatomy of a Neural Network
A deep learning model is built from layers of interconnected nodes called neurons — inspired loosely by the structure of the human brain. Here’s the basic architecture:
- Input Layer — Receives raw data (pixels, words, numbers).
- Hidden Layers — One or more layers where transformation and learning happen. More hidden layers = “deeper” network.
- Output Layer — Produces the final prediction (e.g., “cat,” “fraud,” “buy”).
Each connection between neurons has a weight — a number that controls how much influence one neuron has over another. During training, the network adjusts these weights using an algorithm called backpropagation, guided by an optimizer (typically stochastic gradient descent or Adam).
The Training Loop
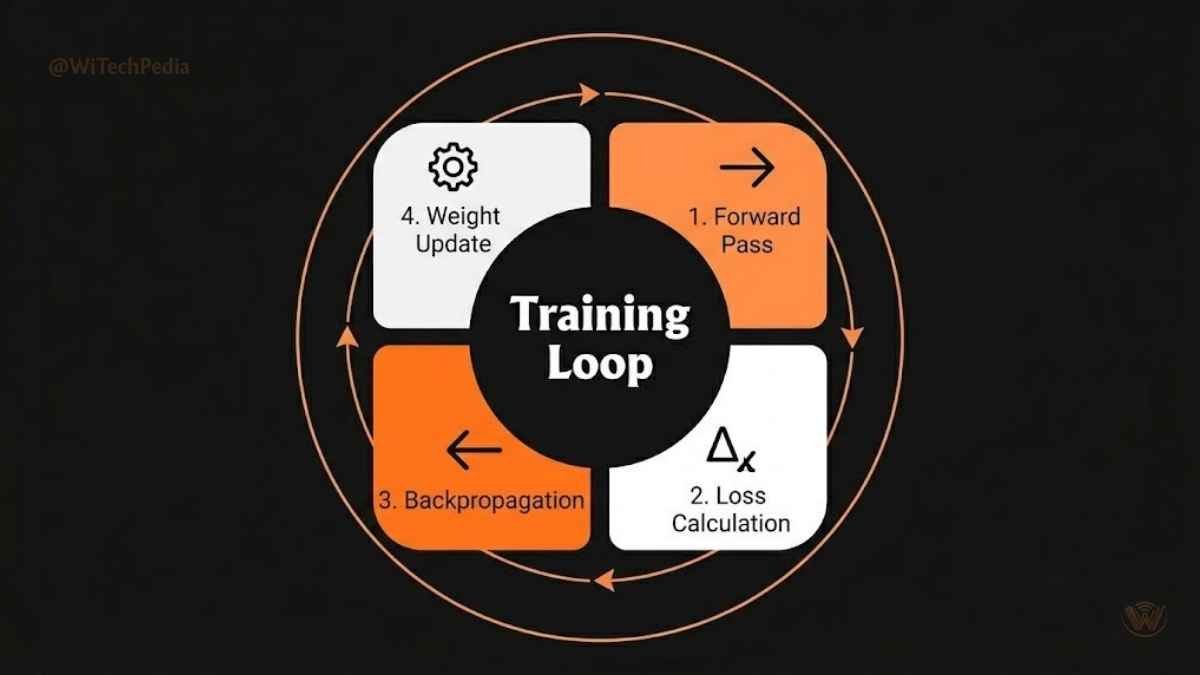
- Forward Pass — Input data flows through the network; a prediction is made.
- Loss Calculation — The model’s prediction is compared to the correct answer using a loss function (e.g., cross-entropy for classification).
- Backward Pass (Backpropagation) — The error is propagated back through the network; weights are updated to reduce the loss.
- Repeat — This cycle runs for thousands or millions of iterations across the training dataset.
The result? A model that has learned to generalize — to make good predictions on data it has never seen before.
Activation Functions
Without non-linearity, stacking layers would just be fancy matrix multiplication — linear transformations can’t capture complex patterns. Activation functions introduce non-linearity:
- ReLU (Rectified Linear Unit) — The workhorse of modern deep learning. Simple, fast, effective.
- Sigmoid — Squashes output to (0, 1); used in binary classification output layers.
- Softmax — Converts outputs to probabilities; used in multi-class classification.
- Tanh — Outputs in (-1, 1); used in recurrent networks and some generative models.
Core Architectures in Deep Learning
Convolutional Neural Networks (CNNs)
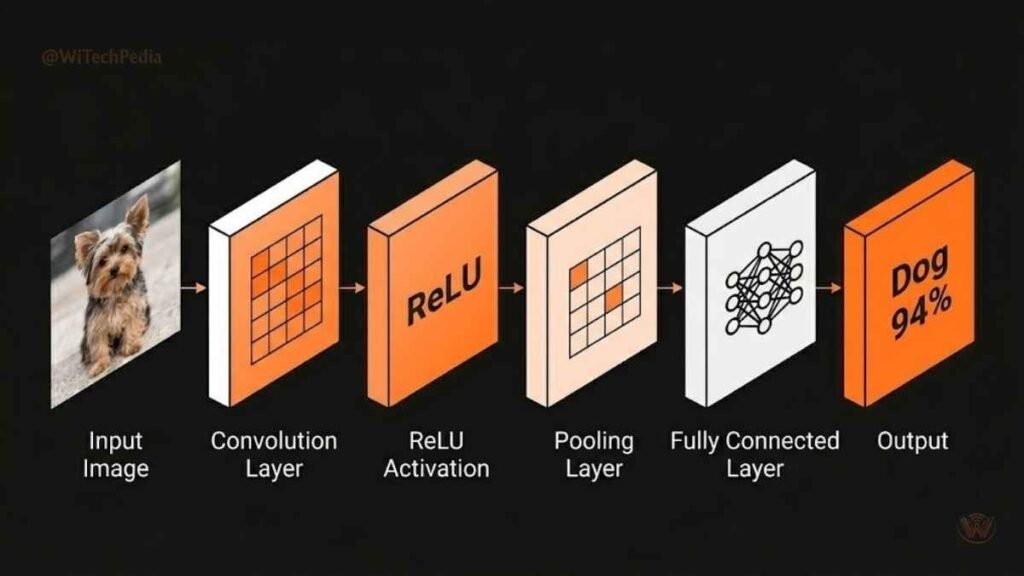
CNNs are the backbone of computer vision. They apply learned filters (kernels) across an image to detect spatial patterns — edges, textures, objects. Key operations include convolution, pooling, and fully connected layers.
Real-world use: Medical imaging (detecting tumors), autonomous vehicles (object detection), facial recognition.
Landmark CNN architectures:
- AlexNet (2012) — The model that started the deep learning boom.
- VGGNet (2014) — Deeper, simpler, influential on architecture design.
- ResNet (2015) — Introduced skip connections to train networks 100+ layers deep without degradation.
- EfficientNet (2019) — Scales depth, width, and resolution systematically for best accuracy-efficiency trade-off.
Recurrent Neural Networks (RNNs) and LSTMs
RNNs process sequences — they have loops that allow information to persist across time steps. This makes them suited for time-series data, language, and speech.
The problem: Vanilla RNNs suffer from the vanishing gradient problem, where gradients shrink to near-zero as they propagate back through long sequences, making long-range dependencies hard to learn.
The solution: Long Short-Term Memory (LSTM) networks use gating mechanisms to selectively remember or forget information over long sequences.
Real-world use: Speech recognition, machine translation, sentiment analysis, stock forecasting.
Transformers
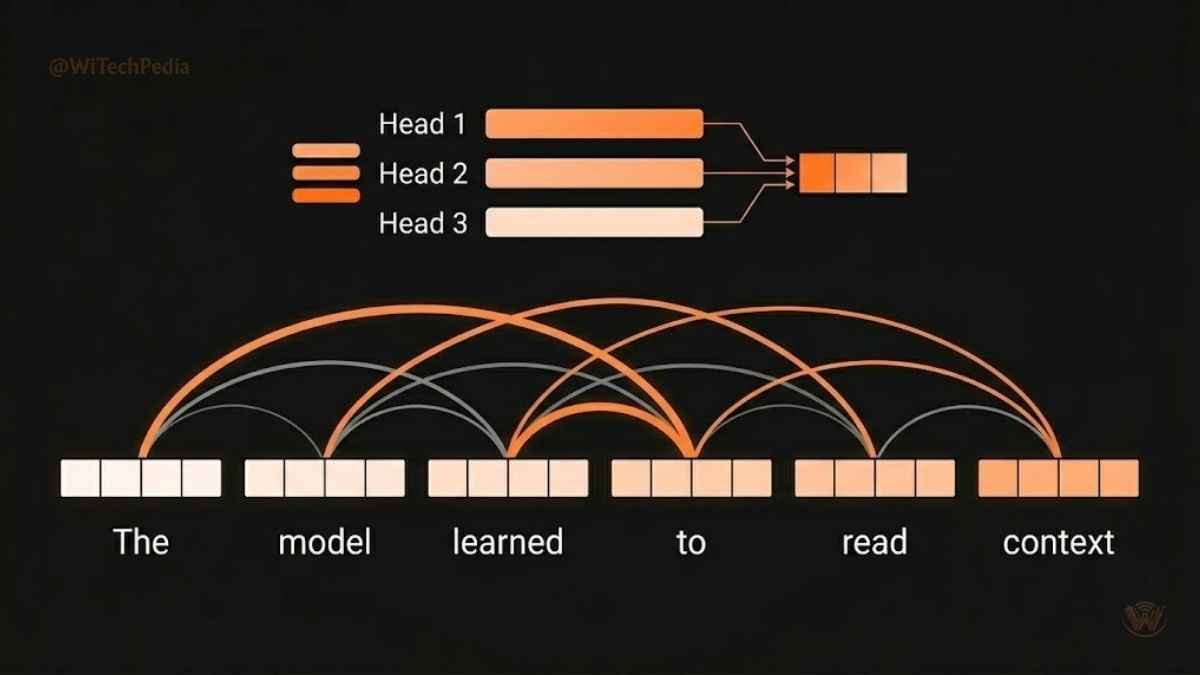
Introduced in the landmark 2017 paper “Attention Is All You Need,” Transformers replaced RNNs as the dominant architecture for natural language processing (NLP). They use self-attention mechanisms to weigh the importance of every word in a sequence relative to every other word — simultaneously, not sequentially.
This parallelism enabled training on massive datasets, giving rise to:
- BERT (Google, 2018) — Bidirectional encoder; excels at understanding tasks.
- GPT series (OpenAI) — Autoregressive decoder; excels at generation tasks.
- Vision Transformers (ViT) — Applied transformer architecture to image patches, challenging CNNs on vision tasks.
Real-world use: Large Language Models (LLMs), code generation, question answering, summarization.
Generative Adversarial Networks (GANs)
Proposed by Ian Goodfellow in 2014, GANs pit two networks against each other:
- Generator — Creates synthetic data (images, audio, text).
- Discriminator — Tries to distinguish real from fake.
They train together in a minimax game until the generator creates data indistinguishable from real data.
Real-world use: Image synthesis, deepfake detection, drug discovery, data augmentation.
Diffusion Models
The newest frontier in generative AI. Diffusion models learn to denoise progressively noisier versions of data — and at inference, start from pure noise and reverse the process to generate images or audio.
Real-world use: Stable Diffusion, DALL·E, Midjourney, Sora (video generation).
Deep Learning Frameworks: The Developer’s Toolkit
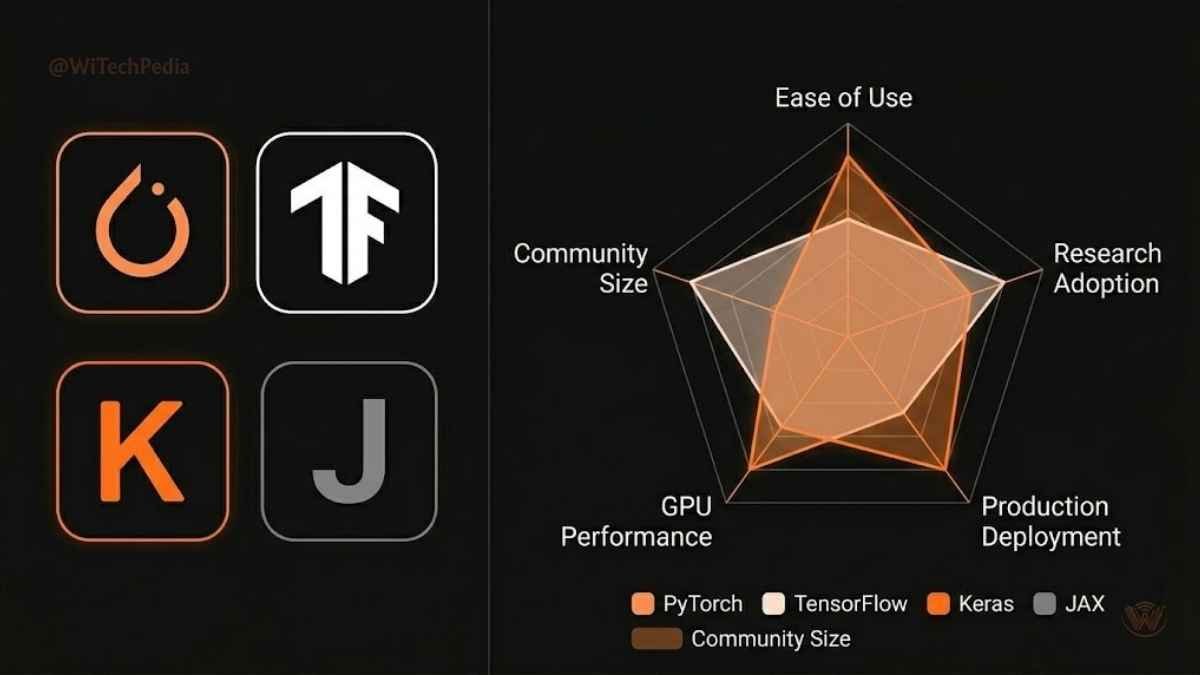
Choosing the right framework is foundational. Here’s how the major ones compare:
| Framework | Developed By | Primary Use Case | Strengths | Best For |
|---|---|---|---|---|
| TensorFlow | Production, Mobile (TFLite) | Deployment, ecosystem maturity | Enterprise & edge AI | |
| PyTorch | Meta (Facebook) | Research, Prototyping | Dynamic graphs, Pythonic API | Research & academia |
| Keras | Google (now Keras 3) | High-level API | Simplicity, beginner-friendly | Rapid prototyping |
| JAX | Google DeepMind | Scientific computing | Functional style, XLA compilation | TPU-heavy research |
| MXNet | Apache | Multi-GPU training | Scalability | Large-scale distributed training |
| ONNX | Microsoft/Meta | Model interoperability | Cross-framework deployment | Production pipelines |
Industry trend: PyTorch now dominates research publications and has grown significantly in production usage, while TensorFlow remains strong in mobile and embedded deployment via TFLite and TF Serving.
For a deeper comparison, see: Best Deep Learning Frameworks in 2026
Real-World Applications of Deep Learning
Deep learning is not an academic curiosity — it is reshaping entire industries:
Healthcare & Medicine
- Radiology AI: Google’s DeepMind developed an eye disease detection model that matched the accuracy of world-class ophthalmologists.
- Drug Discovery: Recursion Pharmaceuticals uses CNNs to analyze millions of cell images and identify drug candidates.
- Genomics: AlphaFold (DeepMind) solved a 50-year-old protein folding problem, predicting 3D protein structures with near-atomic accuracy.
Autonomous Vehicles
Companies like Waymo and Tesla use deep learning (primarily CNNs and Transformers) for real-time object detection, lane recognition, depth estimation, and path planning. See: How Self-Driving Cars Work
Natural Language Processing
Every modern NLP application — ChatGPT, Google Search’s understanding of queries, real-time translation (DeepL, Google Translate) — runs on Transformer-based deep learning models.
Cybersecurity
Deep learning models analyze network traffic patterns to detect anomalies and zero-day threats with far higher precision than rule-based systems.
Gaming & Entertainment
NVIDIA’s DLSS (Deep Learning Super Sampling) uses neural networks to upscale game graphics in real time, delivering 4K-quality visuals at lower computational cost.
Finance
Fraud detection, algorithmic trading signals, credit scoring, and document processing all increasingly rely on deep learning systems trained on transactional data.
Key Challenges in Deep Learning

Deep learning is powerful — but not magic. Serious challenges remain:
- Data Hunger: Deep models require enormous labeled datasets. Collecting and labeling data is expensive and time-consuming.
- Compute Cost: Training frontier models costs tens of millions of dollars. OpenAI reportedly spent over $100M training GPT-4.
- Black Box Problem: Deep networks are notoriously hard to interpret. Explainable AI (XAI) is an active research field addressing this.
- Bias & Fairness: Models trained on biased data amplify those biases in predictions — a critical concern in hiring, lending, and law enforcement applications.
- Adversarial Attacks: Small, imperceptible perturbations to input data can fool deep learning models into catastrophically wrong predictions.
- Energy Consumption: Training a large language model can emit as much CO₂ as five transatlantic flights.
The Hardware Powering Deep Learning
Modern deep learning runs on specialized hardware:
- GPUs (Graphics Processing Units): NVIDIA’s A100 and H100 GPUs are the workhorses of deep learning. Their massively parallel architecture is ideal for matrix multiplications at scale. See: Best GPUs for AI 2025
- TPUs (Tensor Processing Units): Google’s custom ASICs, optimized for TensorFlow workloads. Available via Google Cloud.
- NPUs (Neural Processing Units): Dedicated AI accelerators now built into consumer chips — Apple’s Neural Engine, Qualcomm’s Hexagon, Intel’s NPU.
- Neuromorphic Chips: Experimental hardware (Intel’s Loihi) that mimics brain-like spiking neuron architectures for ultra-efficient inference.
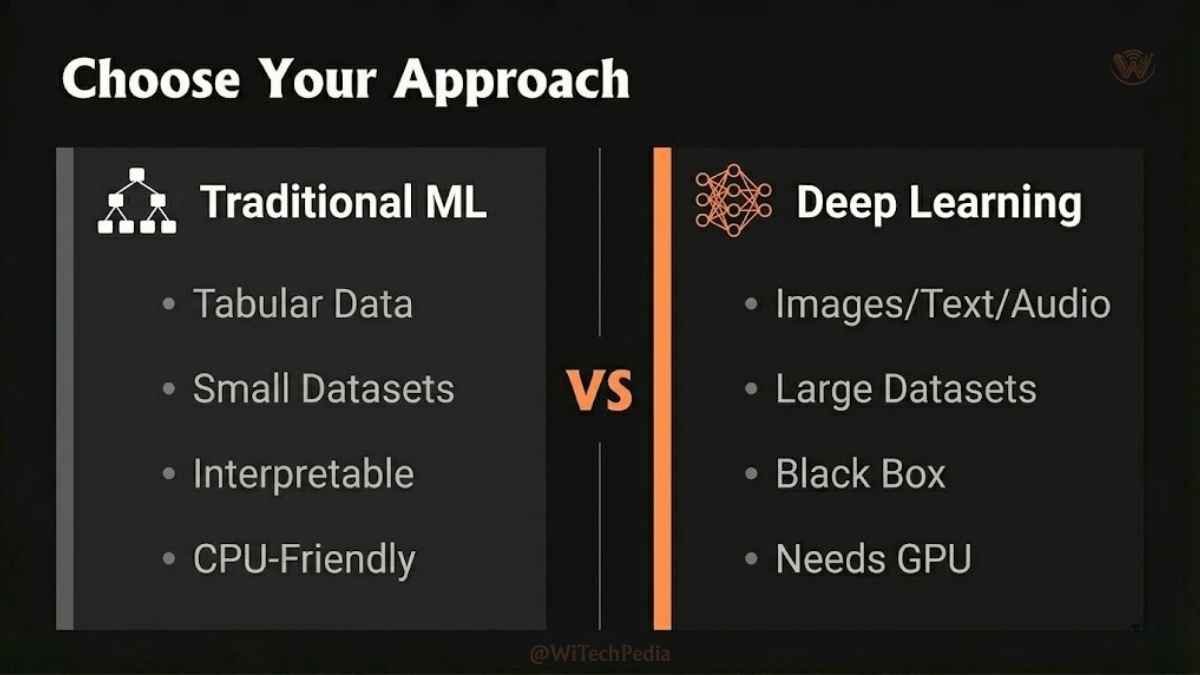
Deep Learning vs. Machine Learning: When to Use Which
| Criteria | Traditional Machine Learning | Deep Learning |
|---|---|---|
| Data Size | Works well with small-medium datasets | Requires large datasets (typically 100K+ samples) |
| Feature Engineering | Manual feature selection required | Automated feature learning |
| Interpretability | Generally more interpretable | Often a black box |
| Compute Required | Runs on CPU efficiently | Typically needs GPU/TPU |
| Best For | Tabular data, small datasets | Images, audio, text, video |
| Training Time | Minutes to hours | Hours to weeks |
| Examples | Random Forest, XGBoost, SVM | CNNs, Transformers, GANs |
Rule of thumb: If your data is tabular and structured, XGBoost still often beats deep learning. If it’s unstructured (images, speech, text) and you have enough of it — deep learning wins decisively.
Getting Started with Deep Learning
For Beginners
- Learn Python — The lingua franca of AI. See: Python for Beginners
- Master NumPy & Linear Algebra — Vectors, matrices, dot products are foundational.
- Take a Structured Course — fast.ai (top-down, practical) or deeplearning.ai by Andrew Ng (bottom-up, rigorous).
- Build with Keras — Start with simple classification models on MNIST or CIFAR-10.
- Graduate to PyTorch — Once comfortable, move to PyTorch for research-grade work.
Recommended Resources
- Books: Deep Learning by Goodfellow, Bengio & Courville (free online at deeplearningbook.org); Hands-On Machine Learning by Aurélien Géron.
- Platforms: Google Colab for free GPU access; Kaggle for datasets and competitions.
- Papers: arXiv.org cs.LG for the latest deep learning research.
Frequently Asked Questions (FAQs)
What is deep learning in simple terms?
Deep learning is a type of artificial intelligence that teaches computers to learn from examples, much like humans do. It uses layered networks of mathematical functions — called neural networks — to recognize patterns in data like images, sounds, and text. The more layers, the more complex patterns the system can learn.
What is the difference between deep learning and machine learning?
Machine learning is the broader field of building systems that learn from data. Deep learning is a specific technique within ML that uses multi-layered neural networks. Traditional ML requires humans to manually define which features to extract from data; deep learning discovers those features automatically. Deep learning generally outperforms traditional ML on unstructured data (images, audio, text) when sufficient data is available.
What are the best deep learning frameworks for beginners?
Keras (built on TensorFlow) is widely recommended for beginners due to its clean, readable syntax and extensive documentation. PyTorch is the preferred choice for researchers and those who want to understand what’s happening under the hood. Both are Python-based, open source, and have massive communities and tutorial ecosystems.
How much data do you need for deep learning?
There’s no universal answer, but a common rule of thumb is at least 10,000 labeled examples per class for basic image classification tasks. Frontier models like GPT-4 were trained on trillions of tokens of text. Techniques like transfer learning and data augmentation can help when data is scarce — you can fine-tune a pre-trained model on as few as a few hundred examples for specialized tasks.
Is deep learning the same as AI?
No. AI is the broadest concept — any machine that simulates intelligent behavior. Deep learning is a specific methodology within AI. Not all AI uses deep learning; rule-based systems, expert systems, and classical ML are all forms of AI that don’t involve deep neural networks.
What is transfer learning in deep learning?
Transfer learning is the practice of taking a neural network pre-trained on a large dataset (like ImageNet or a large text corpus) and fine-tuning it on a smaller, task-specific dataset. Instead of training from scratch, you start with a model that already understands general features and teach it the specifics of your problem. This dramatically reduces the data and compute required — and is why models like BERT and GPT can be adapted to specialized domains efficiently.
What industries are most transformed by deep learning?
Healthcare (diagnostics and drug discovery), autonomous vehicles, finance (fraud detection), entertainment (recommendation systems, generative AI), and cybersecurity are among the most deeply impacted. The technology is now sufficiently mature that virtually every data-intensive industry is integrating deep learning into core operations.
The Future of Deep Learning
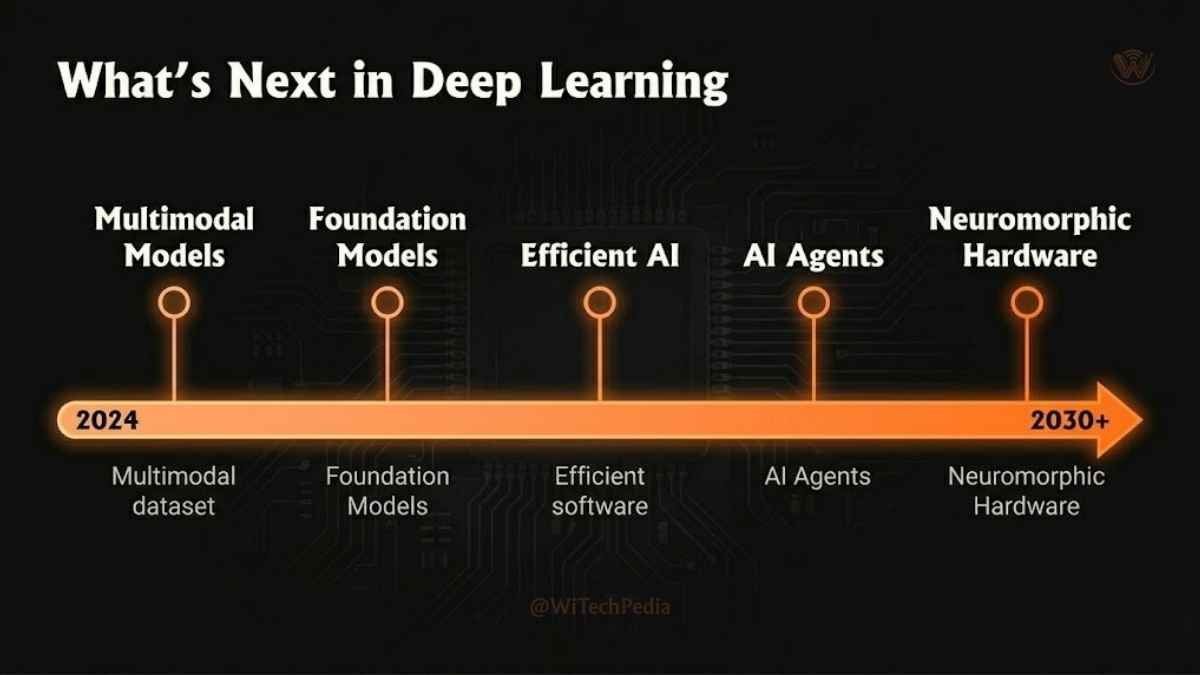
The pace of progress shows no sign of slowing. Several frontiers are particularly exciting:
- Multimodal Models: Systems like GPT-4o and Gemini Ultra process text, image, audio, and video simultaneously — collapsing the boundary between modalities.
- Efficient AI: Researchers are developing smaller, faster, less energy-hungry models. Techniques like quantization, pruning, and knowledge distillation are making powerful models accessible on edge devices.
- Foundation Models: Massive pre-trained models are becoming general-purpose platforms that can be adapted (fine-tuned) to thousands of downstream tasks with minimal additional data.
- AI Agents: Deep learning is powering autonomous agents that can use tools, browse the web, write and execute code, and complete multi-step tasks with minimal human intervention. See: What Are AI Agents?
- Neuromorphic Computing: Long-term, brain-inspired hardware may one day enable deep learning inference at a fraction of current energy costs.
Conclusion: Why Deep Learning Is the Most Important Technology of Our Era
Deep learning has fundamentally changed what machines can do — and the transformation is still in its early chapters.
Key takeaways from this guide:
- Deep learning is a subfield of ML that uses multi-layered neural networks to automatically learn features from data — no manual feature engineering required.
- Core architectures — CNNs, RNNs/LSTMs, Transformers, GANs, and Diffusion Models — each excel at different data types and tasks.
- The dominant frameworks are PyTorch (research) and TensorFlow/Keras (production), though the ecosystem is rapidly evolving.
- Real-world impact is massive — from diagnosing diseases to generating synthetic media to enabling self-driving cars.
- Challenges remain — data hunger, compute cost, interpretability, and bias are active areas of research and policy debate.
The best time to understand deep learning is now. The technology is accessible, the resources are free, and the opportunity to build something genuinely transformative has never been greater.
Stay ahead of AI and technology breakthroughs. Subscribe to the WiTechPedia newsletter for weekly deep-dives, tutorials, and reviews — delivered straight to your inbox.