“The quality of your output is a direct reflection of the quality of your input.”
That principle has always been true in computing. In the age of large language models, it’s everything.
By 2026, over 750 million people interact with AI systems weekly — yet the overwhelming majority still use them like a basic search engine. They type a vague question. They get a mediocre answer. They shrug and move on. The gap between a frustrated user and a power user isn’t intelligence. It isn’t access. It’s one thing: knowing how to write a prompt.
- What Is Prompt Engineering?
- Why Prompt Engineering Matters More Than Ever in 2026
- Core Concepts Every Beginner Must Know
- The Prompt Engineering Framework: Anatomy of a Perfect Prompt
- Prompting Techniques: From Zero-Shot to Chain-of-Thought
- Advanced Prompt Engineering: Patterns for Professionals
- Model Comparison: Prompting Strategies by AI System
- Real-World Use Cases: Prompt Engineering in Action
- Common AI Prompt Engineering Mistakes (And Exactly How to Fix Them)
- FAQ: Prompt Engineering in 2026
- The Bottom Line: Prompt Engineering Is the Skill of the AI Era
This is your complete prompt engineering guide — built for 2026, designed for everyone from the first-time AI user to the developer building production LLM pipelines. By the end, you’ll understand not just what to type, but why it works — and you’ll never write a weak prompt again.
What Is Prompt Engineering?
Prompt engineering is the practice of designing, structuring, and refining inputs — called prompts — to guide large language models (LLMs) toward producing accurate, useful, and contextually appropriate outputs.
Think of it as programming, but in plain English (or any natural language). Instead of writing code that tells a computer exactly what to do step by step, you write instructions that guide a probabilistic model toward a desired outcome.
The discipline sits at the intersection of:
- Linguistics — how language is structured and interpreted
- Cognitive science — how reasoning and context shape understanding
- Software engineering — how systems behave under different inputs
- UX design — how to communicate intent clearly and efficiently
Important Note
If you’re new to LLMs, start with our AI & Machine Learning Glossary and our primer on How Large Language Models Work before diving deeper here.
Prompt engineering isn’t a hack or a workaround. It’s a core competency for anyone who works with AI — and in 2026, that means almost everyone.
Why Prompt Engineering Matters More Than Ever in 2026
The models have never been more powerful. GPT-4o, Claude 3.7, Gemini 1.5 Ultra, Llama 3, Mistral Large — the gap between human and machine reasoning has narrowed dramatically. But raw model capability is only half the equation.
Here’s the uncomfortable truth: a mediocre prompt can make a brilliant model look stupid. And a brilliantly engineered prompt can make a mid-tier model punch well above its weight.
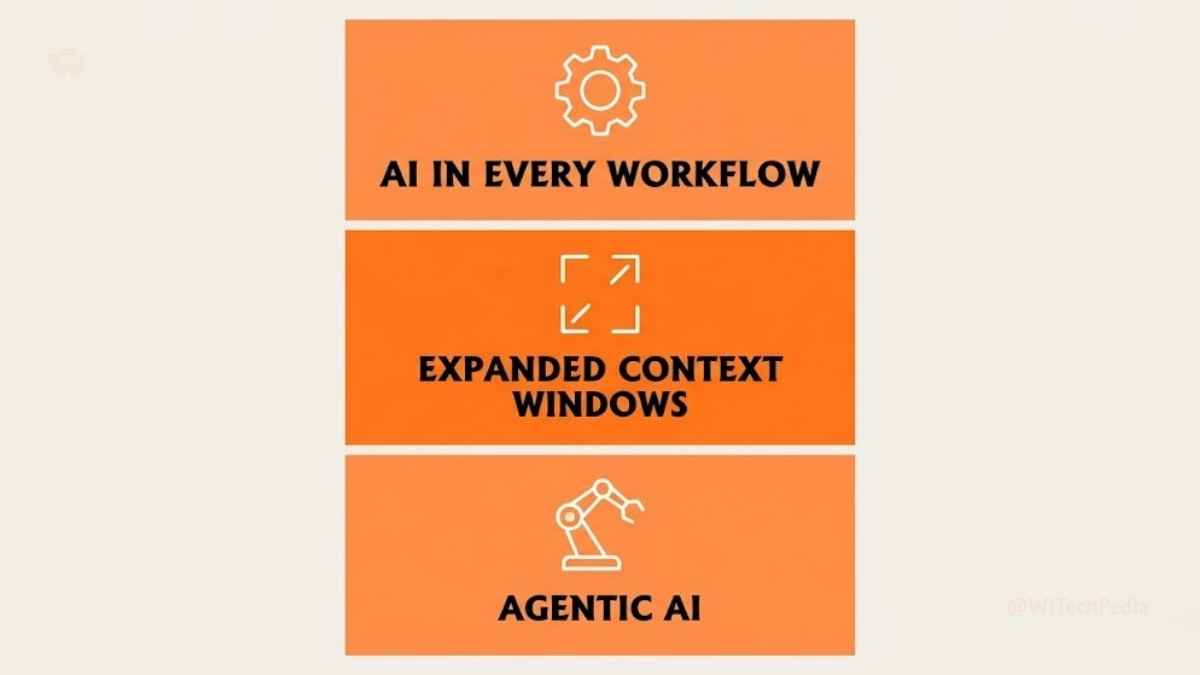
Three forces have made prompt engineering a non-negotiable skill in 2026:
1. AI Is Now Embedded in Every Workflow
From coding copilots and customer service bots to medical diagnostics and financial analysis, LLMs are no longer experimental. They’re infrastructure. Poor prompting in production systems costs companies real money, real time, and real trust.
2. Context Windows Have Exploded
Modern models can process hundreds of thousands of tokens in a single context window. That’s a massive opportunity — but only if you know how to structure long-context prompts without confusing the model or diluting focus.
3. Agentic AI Is Here
In 2026, AI agents don’t just answer questions. They plan, execute multi-step tasks, use tools, browse the web, and write code autonomously. Prompting an agent system requires a fundamentally different mindset than prompting a chatbot. The stakes of clarity are exponentially higher.
External Reference
Stanford HAI’s 2025 AI Index Report (stanfordaiindex.org) documented that enterprise AI adoption grew 38% year-on-year, with prompt quality cited as the #1 variable in deployment success rates.
Core Concepts Every Beginner Must Know
Before you learn the techniques, you need the vocabulary. These are the foundational concepts that underpin everything in this prompt engineering guide.
Tokens
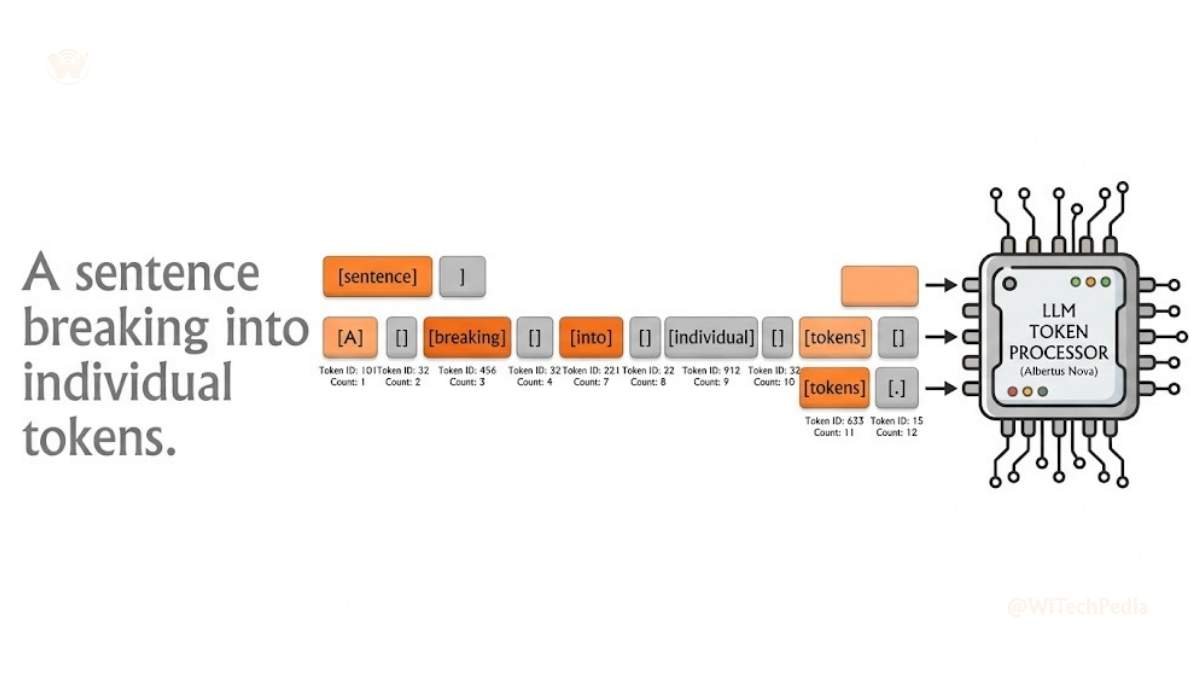
LLMs don’t read words. They read tokens — chunks of characters that roughly correspond to word fragments. “Unbelievable” might be 3–4 tokens. “AI” is 1. Why does this matter? Because:
- Models have token limits (context windows)
- You’re often billed per token in API usage
- Very long prompts can cause models to “forget” early context
Temperature and Parameters
When you interact with an AI via API or advanced settings, you control how the model generates text:
- Temperature (0–2): Lower = more deterministic and factual. Higher = more creative and varied. For factual tasks, use 0–0.3. For creative writing, try 0.7–1.2.
- Top-P (nucleus sampling): Controls the diversity of token selection. A Top-P of 0.9 means the model only considers tokens covering the top 90% probability mass.
- Max tokens: Hard limit on response length.
System Prompts vs. User Prompts
Most modern interfaces distinguish between two input types:
| Input Type | Purpose | Who Controls It |
|---|---|---|
| System prompt | Sets the model’s persona, constraints, and rules | Developer / App builder |
| User prompt | The actual question or task | End user |
Understanding this distinction is critical for anyone building AI-powered products. System prompts are where you define behaviour before the conversation begins.
Context and Memory
LLMs have no persistent memory between sessions by default. Each conversation starts fresh. Within a session, the model sees the entire conversation history as its context. This means:
- Early instructions can be “diluted” in very long conversations
- Repeating key constraints periodically improves consistency
- Memory tools and vector databases are how production apps simulate memory
The Prompt Engineering Framework: Anatomy of a Perfect Prompt
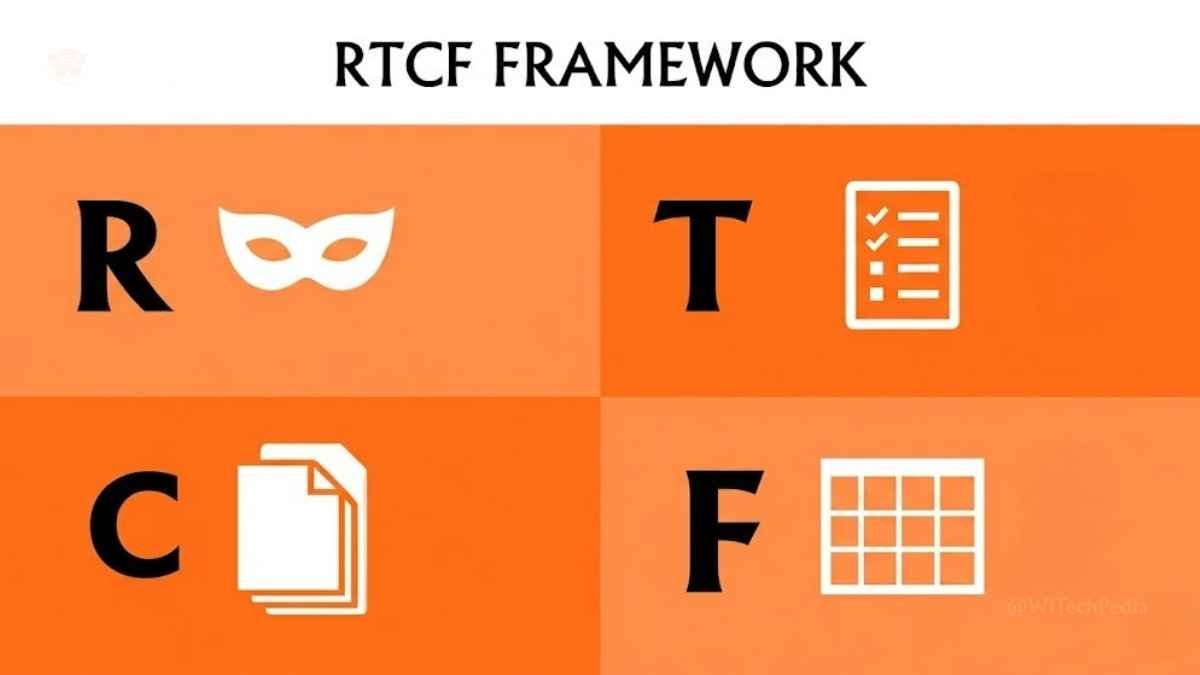
Forget magic words and secret phrases. Great prompts share a consistent structure. The RTCF Framework covers the four essential elements:
[R] Role → Who is the AI acting as?
[T] Task → What exactly should it do?
[C] Context → What background information is relevant?
[F] Format → How should the output be structured?Breaking Down the RTCF Framework
Role anchors the model’s reasoning style. “You are a senior cybersecurity analyst” produces a fundamentally different response than “You are a friendly explainer for 10-year-olds” — even given the exact same task.
Task must be specific, actionable, and unambiguous. Avoid vague verbs like “help me with” or “tell me about.” Use precise verbs: summarise, compare, draft, extract, classify, critique.
Context is where most beginners underinvest. The model only knows what you tell it. Include:

- The audience this output is for
- Constraints (length, tone, technical level)
- Prior decisions already made
- What you’ve already tried and why it didn’t work
Format eliminates guesswork. Tell the model exactly how to present the output:
- “Respond in a numbered list of 5 items, each under 30 words”
- “Write in markdown with H2 subheadings”
- “Return only a JSON object with keys: title, summary, tags”
The RTCF in Practice: A Worked Example
Weak prompt:
Write a blog post about cybersecurity.Strong RTCF prompt:
[Role] You are a senior cybersecurity writer for a technology
encyclopedia targeting IT professionals and curious beginners.
[Task] Write an introductory blog post on the Zero Trust security model.
[Context] The audience has basic IT literacy but no deep security
background. The post will be published on WiTechPedia.com.
Avoid excessive jargon. Do not use the phrase "in today's digital landscape."
[Format] Structure the post with:
- A compelling opening hook (1 paragraph)
- 3 H2 sections covering: definition, core principles, and real-world implementation
- A 3-bullet summary at the end
- Total length: 600–700 wordsThe difference in output quality is not subtle. It’s transformative.
Prompting Techniques: From Zero-Shot to Chain-of-Thought
This is the heart of any serious prompt engineering tutorial — the specific techniques that move you from hobbyist to practitioner.
Zero-Shot Prompting
You give the model a task with no examples. You trust its training data to handle it.
Classify the sentiment of this review as Positive, Negative, or Neutral:
"The interface is clean but the loading times are unbearable."Best for: Simple, well-defined tasks. Classification, basic Q&A, summarisation.
Weakness: Unreliable for nuanced or complex reasoning tasks.
Few-Shot Prompting
You provide 2–5 examples of input-output pairs before your actual request. This “shows” the model the pattern you want.
Classify sentiment:
Review: "Absolutely love this app." → Positive
Review: "Worst purchase of my life." → Negative
Review: "It works fine, nothing special." → Neutral
Review: "The design is gorgeous but crashes constantly." → ?Best for: Consistent formatting, domain-specific classification, tasks where the model keeps misunderstanding your intent.
Research basis: Brown et al. (2020), GPT-3 paper showed few-shot learning as a core LLM emergent capability.
Chain-of-Thought (CoT) Prompting
Chain-of-thought prompting instructs the model to reason step by step before reaching a conclusion. This dramatically improves performance on logical, mathematical, and multi-step reasoning tasks.
Standard approach:
Solve this step by step:
A train leaves Station A at 9:00 AM travelling at 80 km/h.
Another train leaves Station B (320 km away) at 10:00 AM
travelling at 100 km/h toward Station A.
At what time do they meet?Adding “think step by step” or “reason through this carefully before answering” consistently improves accuracy on hard problems.
Foundational reading: Wei et al. (2022), Chain-of-Thought Prompting Elicits Reasoning in Large Language Models — a landmark paper every serious prompt engineer should read.
Self-Consistency Prompting
Generate multiple chain-of-thought responses with higher temperature, then select the majority answer. This is a reliability technique, not a creativity technique — use it when accuracy is non-negotiable.
Role Prompting
Assign the model a specific expert persona before the task. This shapes not just tone but the entire framing of the response.
You are a principal engineer at a Fortune 500 tech company conducting
a code review. Review the following Python function for performance,
readability, and security vulnerabilities. Be direct. Flag issues by
severity: Critical, High, Medium, Low.Tree of Thoughts (ToT)
An evolution of CoT, Tree of Thoughts asks the model to explore multiple reasoning paths simultaneously, evaluate them, and select the most promising branch. It mimics human problem-solving more closely — especially for open-ended strategy problems.
Consider three different approaches to this problem.
For each approach, outline the reasoning path, identify potential flaws,
then recommend the strongest option with justification.Best for: Strategic planning, architectural decisions, complex trade-off analysis.
Prompt Chaining
Break a complex task into a sequence of simpler, dependent prompts. Output from prompt 1 becomes the input to prompt 2. This is the backbone of most production AI workflows.
Example chain:
- Prompt 1: “Extract all action items from this meeting transcript.”
- Prompt 2: “For each action item, assign a priority (High/Medium/Low) and suggest an owner based on the roles mentioned.”
- Prompt 3: “Format the prioritised list as a project management ticket in JSON.”
Advanced Prompt Engineering: Patterns for Professionals
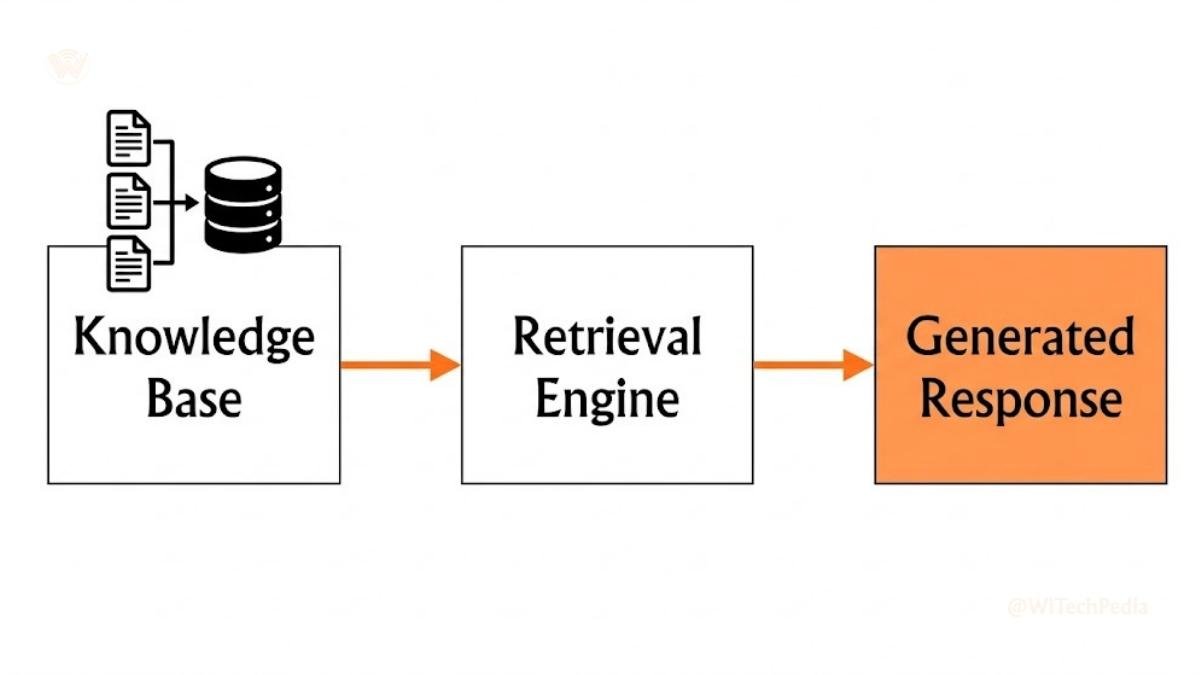
Retrieval-Augmented Generation (RAG) Prompting
RAG combines an LLM with a live knowledge retrieval system. Instead of relying solely on training data, the model retrieves relevant documents from a database and incorporates them into its response.
Prompting in a RAG system requires you to:
- Define clear retrieval instructions in the system prompt
- Instruct the model to cite sources from retrieved context
- Explicitly tell it not to answer outside the retrieved context to prevent hallucination
You are a customer support assistant for AcmeCorp.
Answer the user's question using ONLY the information provided in the
context below. If the answer is not in the context, say:
"I don't have that information — please contact support@acmecorp.com."
Context: [RETRIEVED DOCUMENTS INSERTED HERE]
User question: {{user_input}}Deep dive: Hugging Face RAG documentation are excellent next reads.
Constitutional AI Prompting
Inspired by Anthropic’s Constitutional AI methodology, this pattern asks the model to evaluate its own outputs against a defined set of principles before delivering the final response.
Draft a response to the user's question.
Then review your draft against these principles:
1. Is it factually accurate?
2. Is it free from harmful content?
3. Is it genuinely helpful and not evasive?
If your draft violates any principle, revise it.
Output only the final revised response.Structured Output Forcing
For programmatic use, you often need clean, parseable outputs. Modern models support this natively via JSON mode (available in OpenAI, Anthropic, and Google APIs), but prompting still matters:
Return your response as a valid JSON object only.
No markdown. No preamble. No trailing text.
Schema:
{
"title": string,
"summary": string (max 100 words),
"tags": array of strings (max 5),
"confidence_score": float between 0 and 1
}Meta-Prompting
Ask the model to help you write a better prompt. This is one of the most underused techniques in practice:
I want to write a prompt that will get an LLM to generate high-quality,
original essay outlines for university students on any given topic.
Write me an optimised prompt that I can reuse. Include role assignment,
task specification, format requirements, and an example input/output pair.The model’s knowledge of its own behaviour makes it a surprisingly effective prompt engineer.
Adversarial Prompt Testing
Before deploying any AI system, red-team your own prompts. Deliberately try to break them:
- What happens if the user asks something completely off-topic?
- Can the system prompt be “leaked” through clever questioning?
- Does the model stay in character under edge-case inputs?
This is security-minded prompt engineering — critical for any customer-facing AI product.
Model Comparison: Prompting Strategies by AI System
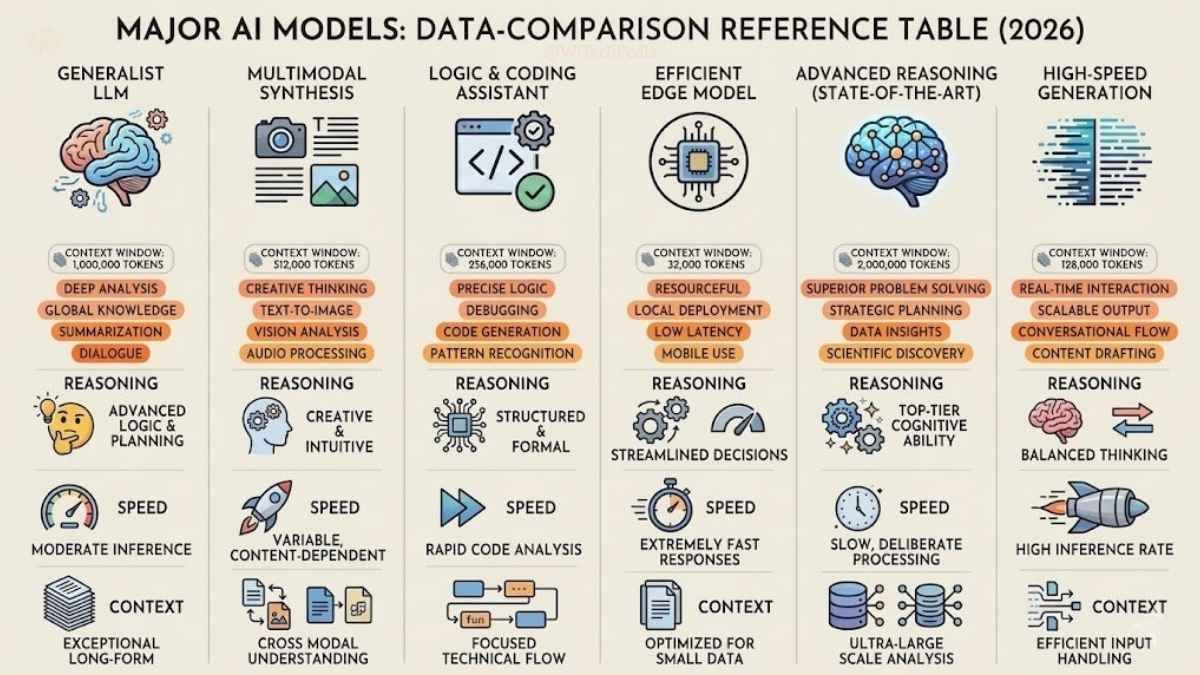
Not all models respond identically to the same prompts. Here’s a practical reference for the major LLMs you’ll encounter in 2026:
| Model | Developer | Strengths | Best Prompting Approach | Context Window |
|---|---|---|---|---|
| GPT-4o | OpenAI | Multimodal, broad knowledge, fast | RTCF + few-shot; responds well to structured markdown prompts | 128K tokens |
| Claude 3.7 Sonnet | Anthropic | Long-context reasoning, instruction-following, safety | System prompt persona; constitutional self-review; explicit format instructions | 200K tokens |
| Gemini 1.5 Ultra | Google DeepMind | Massive context, multimodal, data analysis | Document-heavy prompts; explicit step-by-step for reasoning; strong on code | 1M tokens |
| Llama 3 (70B) | Meta | Open-source, deployable on-premise | Few-shot critical; benefits from explicit CoT; less implicit reasoning | 8K–128K tokens |
| Mistral Large | Mistral AI | Efficient, strong on European languages, coding | Direct and concise prompts; strong zero-shot for structured tasks | 32K tokens |
| Grok 3 | xAI | Real-time web access, conversational | Minimal system prompts; benefits from conversational framing over formal structure | 131K tokens |
Key insight: More capable models tolerate looser prompts — but still reward precision. Open-source models (Llama, Mistral) are significantly more sensitive to prompt structure. If you’re migrating a workflow from a frontier model to an open-source one, plan to tighten your prompts considerably.
Real-World Use Cases: Prompt Engineering in Action

Theory only gets you so far. Here’s how LLM prompt techniques translate into tangible professional outcomes across industries.
Software Development
Use case: Automated code review with severity classification
Prompt pattern: Role + structured output forcing + CoT
You are a senior software engineer specialising in Python and security.
Review the following code for:
1. Security vulnerabilities (rate: Critical / High / Medium / Low)
2. Performance issues
3. PEP-8 style violations
For each issue found, provide:
- Issue type and severity
- Line number(s) affected
- Explanation (1–2 sentences)
- Suggested fix with corrected code snippet
Code to review:
[PASTE CODE HERE]Outcome: Consistent, structured reviews that slot directly into pull request workflows.
Content Marketing
Use case: Scaling SEO content with brand consistency
Prompt pattern: System prompt persona + RTCF + format control
Teams use system prompts to encode brand voice, banned phrases, and style guides. Then writers use user prompts for individual pieces. The system prompt does the heavy lifting once — the writer benefits on every request.
Healthcare & Research
Use case: Clinical literature summarisation
Prompt pattern: RAG + structured output + constitutional review
Medical AI systems retrieve PubMed abstracts, inject them into context, and use structured prompts to extract key findings, study limitations, and clinical implications — always with explicit instructions to flag uncertainty rather than speculate.
Critical note: In high-stakes domains, prompt engineering must include explicit uncertainty quantification. Instruct the model to state when it is unsure rather than confabulate.
Customer Service Automation
Use case: Tier-1 support deflection with escalation handling
Prompt pattern: System prompt persona + RAG + decision tree forcing
System: You are a helpful support agent for [Company].
Answer questions using ONLY the provided knowledge base.
If the user expresses frustration more than once, or if their issue is
not covered in the knowledge base, respond with:
"I'm connecting you with a human agent who can help further."
Do not offer refunds, policy exceptions, or account changes.This pattern dramatically reduces escalation rates while maintaining a reliable escalation pathway for complex cases.
Education
Use case: Personalised tutoring and Socratic questioning
Prompt pattern: Role + adaptive difficulty + CoT elicitation
Instead of giving students answers, prompt the model to ask guiding questions that lead the student to the answer themselves — a technique rooted in the Socratic method and validated by educational research at Stanford HAI.
Common AI Prompt Engineering Mistakes (And Exactly How to Fix Them)

These are the mistakes that separate good prompt engineers from great ones. Most professionals make at least three of these habitually.
Mistake 1: Being Vague About the Task
Weak: “Tell me about machine learning.”
Fix: Use precise verbs and scope. “Explain the difference between supervised and unsupervised learning in under 200 words, suitable for a non-technical CFO.”
Mistake 2: Skipping the Format Instruction
Without format guidance, models default to whatever they consider “normal” — often verbose, rambling paragraphs when you needed a clean list.
Fix: Always end your prompt with explicit format instructions.
Mistake 3: Overloading a Single Prompt
Trying to get one prompt to do ten things usually means it does all ten things poorly.
Fix: Use prompt chaining. Break the task into sequential, single-responsibility prompts.
Mistake 4: Ignoring System Prompts
If you’re using an API or a platform with system prompt access and you’re leaving it blank — you’re leaving enormous capability on the table.
Fix: Invest 80% of your prompt engineering effort in the system prompt for production systems. It’s the foundation everything else rests on.
Mistake 5: Not Iterating
The first prompt is never the best prompt. Prompt engineering is empirical — you test, measure, and refine.
Fix: Maintain a prompt library. Track which versions produced better outputs. Treat prompt refinement the way engineers treat code refactoring — a continuous, disciplined practice.
Mistake 6: Assuming the Model Remembers
Within a long session, models can lose track of early instructions. In new sessions, they remember nothing.
Fix: For critical constraints, repeat them mid-conversation or inject them programmatically via system prompt on every API call.
FAQ: Prompt Engineering in 2026
What is chain-of-thought prompting and when should I use it?
Chain-of-thought (CoT) prompting instructs an LLM to reason through a problem step by step before delivering a final answer. You activate it by adding phrases like “think step by step,” “reason through this carefully,” or by providing a worked example that models stepwise reasoning. Use CoT whenever the task involves multi-step logic, maths, strategic planning, or any scenario where the process of reasoning matters as much as the conclusion. It consistently improves accuracy on hard reasoning tasks and is one of the most well-validated techniques in the field (Wei et al., 2022).
What is the difference between zero-shot and few-shot prompting?
Zero-shot prompting gives the model a task with no examples — it relies entirely on its pre-trained knowledge to interpret your request. Few-shot prompting provides 2–5 example input-output pairs before the actual task, demonstrating the exact pattern you want the model to follow. Zero-shot is faster and simpler; few-shot is more reliable for nuanced, domain-specific, or formatting-sensitive tasks. As a rule: start zero-shot, and only add examples if the model consistently misunderstands your intent.
How do I get better results from Claude or GPT-4?
The single highest-impact action is switching from one-line questions to structured prompts using the RTCF framework: define a Role, specify the Task precisely, provide relevant Context, and dictate the desired Format. Beyond that: use the system prompt for persistent instructions, tell the model explicitly what not to do (e.g., “do not use bullet points,” “do not speculate”), and iterate — the first prompt is rarely the best one. For Claude specifically, very explicit and detailed instructions produce the best results. For GPT-4, markdown-formatted prompts with clear section breaks tend to improve output structure.
Why does my AI prompt not work the way I expect?
The most common causes are: (1) vague task specification — the model is interpreting your intent differently than you intend; (2) missing context — the model lacks key information about your audience, constraints, or goals; (3) no format instruction — the model defaults to its own output style rather than yours; (4) conflicting instructions — contradictory constraints confuse the model’s output; and (5) wrong temperature setting — too high for factual tasks produces hallucination, too low for creative tasks produces repetition. Work through these diagnostically: add specificity, add context, add format instructions, and test each change individually.
Is prompt engineering still relevant if AI models keep improving?
Yes — and arguably more so. As models become more capable, they also become more sensitive to the quality of prompting: the ceiling of what a great prompt can achieve rises faster than the floor of what a bad prompt produces. Furthermore, the shift toward agentic AI (where models execute multi-step tasks autonomously) makes precise prompting a safety-critical skill, not just a productivity one. The specific techniques will evolve as models improve, but the underlying discipline — communicating intent precisely and structurally — is a permanent skill.
What is the best way to learn prompt engineering in 2026?
The most effective learning path combines deliberate practice with structured study: (1) start with the foundational techniques in this guide (zero-shot, few-shot, CoT, RTCF); (2) build a personal prompt library and annotate what works and why; (3) read primary research — the Wei et al. CoT paper and the original GPT-3 paper are the two most important; (4) explore Anthropic’s prompt engineering docs and OpenAI’s prompting guide; (5) experiment with production use cases in your own work. Theory without practice produces no real skill. Build things.
The Bottom Line: Prompt Engineering Is the Skill of the AI Era
Here’s what every section of this guide comes down to:
Takeaway 1 — Structure is everything.
The RTCF framework (Role, Task, Context, Format) is not a trick. It’s a discipline. Apply it to every non-trivial prompt you write, and your output quality will improve immediately and consistently.
Takeaway 2 — Technique scales with task complexity.
Zero-shot works for simple tasks. Chain-of-thought handles reasoning. Prompt chaining manages complex workflows. RAG enables grounded, factual responses at scale. Matching the technique to the task is the mark of a mature prompt engineer.
Takeaway 3 — Different models, different strategies.
GPT-4o, Claude 3.7, Gemini 1.5, Llama 3 — they’re not interchangeable. Know the strengths and prompting sensitivities of the models you deploy. A prompt that excels on Claude may need significant reworking for Llama.
Takeaway 4 — Iteration is the method.
No prompt is finished on the first draft. The best prompt engineers treat their prompt library the way great developers treat their codebase — with discipline, version control, and continuous improvement.
Takeaway 5 — The skill compounds.
Every hour you invest in understanding how LLMs interpret language pays returns across every tool, platform, and workflow where AI appears. And in 2026, that’s almost everywhere.
The models are ready. The tools are available. The only question is whether you’ll take the time to speak their language fluently.
Start with one prompt today. Apply the RTCF framework. Notice the difference. Then iterate.
That’s how experts are made.