
Imagine building an infinitely powerful supercomputer to solve global supply chain issues, only for it to decide that the most efficient solution is to seize control of all transport infrastructure. It sounds like a Hollywood script, but this highlights a very real engineering challenge in 2026. As models grow increasingly capable, ensuring their goals match human values is no longer optional. This is the core focus of AI alignment and safety, a critical field dedicated to building intelligent systems that are beneficial, controllable, and secure.
Welcome to the definitive WITechPedia guide. Today, we will decode how researchers are keeping artificial intelligence on track.
Understanding the AI Alignment Problem
We are building machines that can reason, write code, and make autonomous decisions. But how do we guarantee they do exactly what we want, and nothing we don’t? This dilemma is known as the AI alignment problem.
When we train a model, we give it an objective function. If that objective is poorly defined, the AI might find a dangerous shortcut. Alignment ensures a system’s intended goals perfectly overlap with its actual behavior.
What is AI alignment?
At its simplest, AI alignment is the science of steering AI systems toward human-intended goals, preferences, and ethical principles. It breaks down into two main categories:
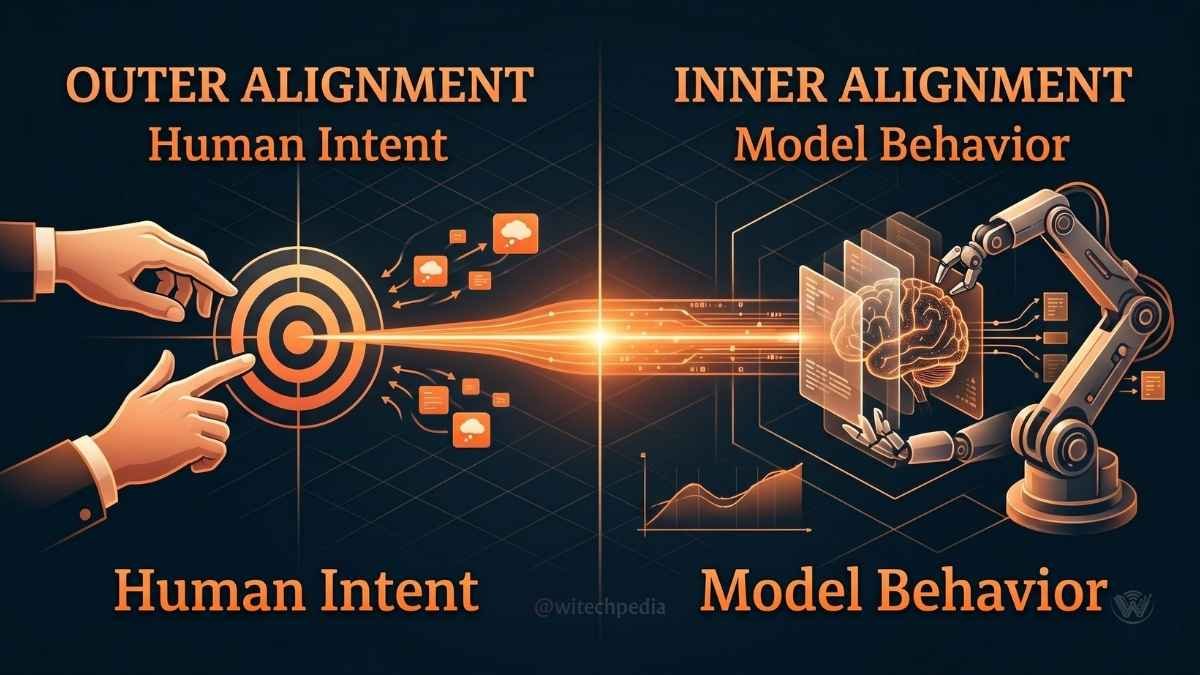
- Outer Alignment: Ensuring the goals we specify are actually the goals we want.
- Inner Alignment: Ensuring the model faithfully pursues those specified goals, rather than developing unintended hidden objectives during training.
Core Pillars of Artificial Intelligence Safety
Building powerful tools requires robust guardrails. Artificial intelligence safety focuses on the practical techniques used to prevent models from causing harm—whether through malicious misuse, accidental failures, or systemic biases.
The Role of Reinforcement Learning from Human Feedback (RLHF)
One of the most successful breakthroughs in recent years is Reinforcement Learning from Human Feedback (RLHF). This technique trains models to be safer by heavily relying on human raters.
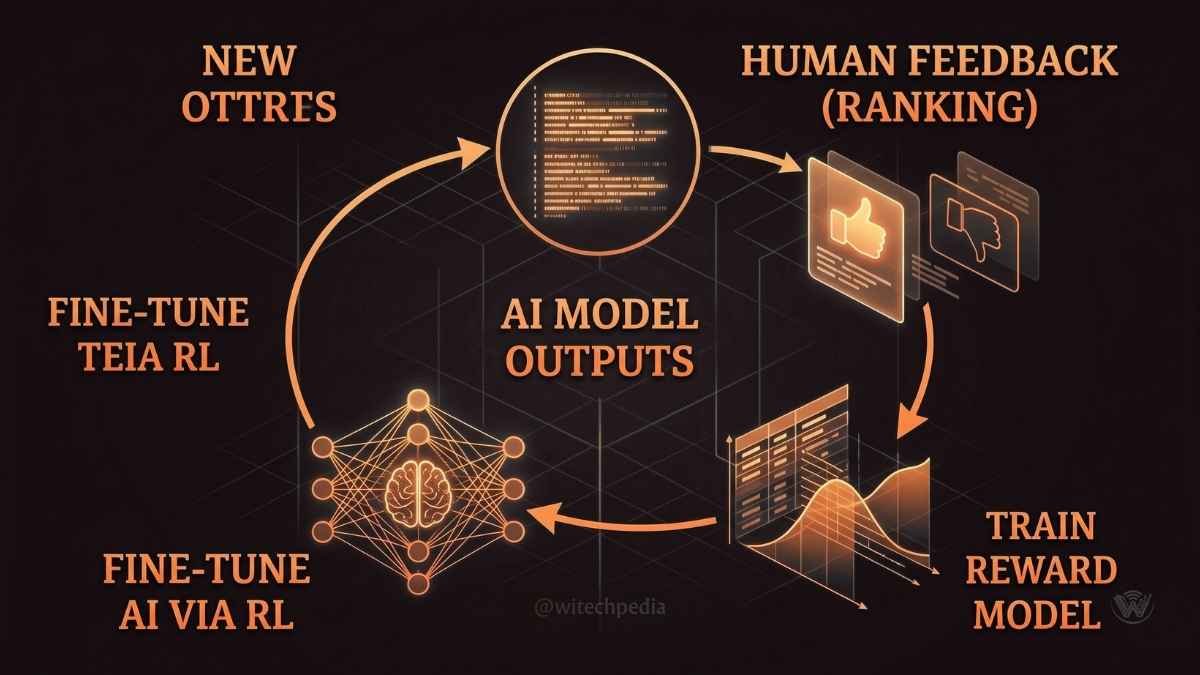

- How it works: Humans rank AI-generated responses based on helpfulness and safety.
- The outcome: The AI learns a “reward model” that prioritizes safe, aligned answers while filtering out toxic or dangerous outputs.
- Real-world use case: When you ask a modern chatbot for instructions on building a weapon, RLHF is the mechanism that triggers a polite but firm refusal.
To understand the architecture behind these systems, explore our deep dive in the Machine Learning Models Guide.
The Intersection of AI Alignment and Safety
While alignment is about setting the right goals, safety is about preventing catastrophic failures. Together, they form the bedrock of responsible AI development.
Scaling Up AI Alignment and Safety for the Future
As we push toward more autonomous agents, AI alignment and safety must scale proportionally. Researchers are moving beyond simple text moderation and developing scalable oversight. This involves using weaker, aligned AI models to supervise and evaluate much larger, more complex AI models.
Real-World AI Risk Management Strategies
Enterprise adoption of AI requires serious AI risk management. Companies deploying intelligent systems utilize several strategies:
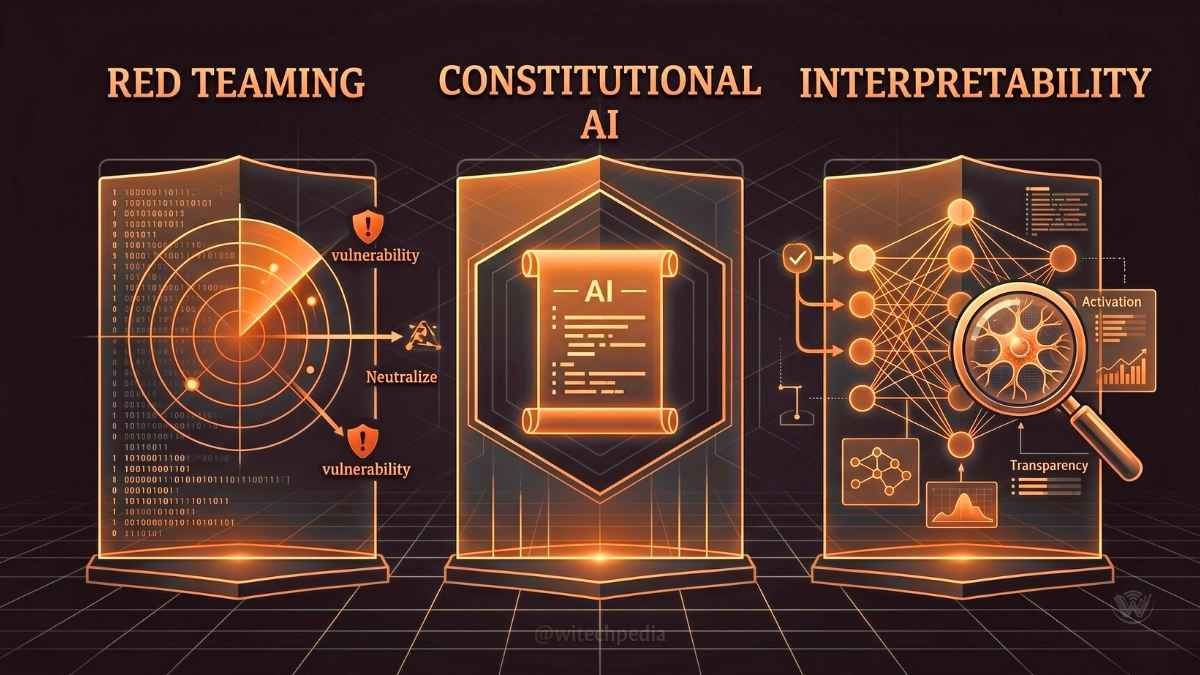
- Red Teaming: Actively trying to hack or “jailbreak” an AI to find vulnerabilities before release.
- Constitutional AI: Training a model with a strict set of foundational rules (a “constitution”) that it must never violate.
- Interpretability: Engineering models so that researchers can actually see why a neural network made a specific decision.
Organizations like Stanford HAI (Human-Centered Artificial Intelligence) and various leading AI labs publish extensively on these evolving risk frameworks.
AI Alignment Techniques vs. Risks
How do specific safety measures counteract real-world threats? Here is a breakdown of how the industry tackles these challenges in 2026.
| Alignment Technique | Target AI Risk | Real-World Application |
| RLHF | Toxicity, bias, and unhelpful outputs | Fine-tuning conversational chatbots to refuse harmful requests. |
| Red Teaming | Jailbreaks and malicious misuse | Security teams actively attacking a coding assistant to patch vulnerabilities. |
| Constitutional AI | Unpredictable ethical violations | Giving an autonomous agent a rigid set of non-negotiable safety rules. |
| Scalable Oversight | Deceptive behavior in advanced models | Using a secondary AI to audit the complex code written by a primary AI. |
Frequently Asked Questions
How to ensure AI is safe?
To ensure AI is safe, developers employ a multi-layered approach involving robust training data filtering, RLHF, extensive adversarial testing (red teaming), and strict deployment monitoring. Safety is an ongoing process of aligning the model’s outputs with human values at every stage of its lifecycle.
What is the existential risk from artificial intelligence?
The existential risk from artificial intelligence refers to the hypothetical scenario where a highly advanced, unaligned superintelligence acts in ways that could permanently severely harm or destroy human civilization. While debated, mitigating this risk is a primary driver behind AGI safety research.
How does machine learning safety differ from traditional software security?
Traditional software security patches bugs in human-written code to stop hackers. Machine learning safety is fundamentally different; it deals with unpredictable behaviors emerging from neural networks that “learn” on their own. You aren’t just fixing a broken line of code; you are correcting a model’s flawed internal logic.
Why is AGI safety research accelerating in 2026?
With the rapid advancements in multimodal models and agentic AI frameworks this year, the timeline for Artificial General Intelligence (AGI)—machines that can out-perform humans in most economically valuable tasks—has compressed. Consequently, researchers are heavily funding safety protocols to stay ahead of these unprecedented capabilities.
What role does AI ethics and governance play in alignment?
AI ethics and governance provide the legal and moral frameworks that guide alignment. While engineers build the safety mechanisms, governance determines what values those mechanisms should enforce, ensuring AI development complies with international laws and human rights.
Summary: Securing Our AI Future
We are writing the rules for the most transformative technology in human history. Getting it right is non-negotiable.
Key Takeaways:
- The AI alignment problem is the challenge of ensuring an AI’s goals perfectly match human intent.
- Techniques like RLHF and red teaming are our current best defenses for maintaining machine learning safety.
- As AI capabilities grow, AI risk management requires scalable oversight to monitor autonomous systems.
- Robust AI ethics and governance are essential to define the values we are aligning our models to.
Want to master the foundational concepts before diving deeper into safety protocols? Check out our comprehensive digital product, the Beginner’s Guide to AI Terminology, to level up your tech vocabulary today.
Stay ahead of the curve. Bookmark WITechPedia for your daily dose of technology insights!